
- Papers 1: Virtual Worlds, VR/AR
- Papers 2: Simulation
- Papers 3: Animation & Voxels
- Papers 4: Filtering & Reconstruction
- Papers 5: Rendering
- Papers 6: Neural & Splatting
Over the past three decades, the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games has showcased exceptional progress from academic and industrial research covering all aspects of interactive computer graphics.
This year, we continue a track record of excellence with 20 high-quality papers selected by the international paper committee for publication and presentation at the conference.
Conference papers have been published in PACM CGIT.
Invited papers
The program also includes 4 papers originally published in the Journal of Computer Graphics Techniques (JCGT) that will be presented during the conference.
Papers 1: Virtual Worlds, VR/AR
- Session chair: Ken Perlin
- VRSplat: Fast and Robust Gaussian Splatting for Virtual Reality
- Xuechang Tu, Lukas Radl, Michael Steiner, Markus Steinberger, Bernhard Kerbl and Fernando de la Torre
- DOI link
-
Abstract
3D Gaussian Splatting (3DGS) has rapidly become a leading technique for novel-view synthesis, providing exceptional performance through efficient software-based GPU rasterization. Its versatility enables real-time applications, including on mobile and lower-powered devices. However, 3DGS faces key challenges in virtual reality (VR): (1) temporal artifacts, such as popping during head movements, (2) projection-based distortions that result in disturbing and view-inconsistent floaters, and (3) reduced framerates when rendering large numbers of Gaussians, falling below the critical threshold for VR.
In this work, we introduce VRSplat, a method that integrates recent advancements in 3DGS to address these challenges. We demonstrate how Mini-Splatting, StopThePop, and Optimal Projection can be effectively combined by modifying both the individual techniques and the core 3DGS rasterizer. Additionally, we propose an efficient foveated rasterizer that handles focus and peripheral areas in a single GPU launch, avoiding redundant computations and improving GPU utilization. Our method also incorporates a fine-tuning step that optimizes Gaussian parameters based on StopThePop depth evaluations and Optimal Projection.
VRSplat is the first 3DGS approach capable of supporting modern VR applications, achieving 72+ FPS while eliminating popping and stereo-disrupting floaters. We validate our method through a controlled user study with 25 participants, showing a strong preference for VRSplat over other configurations of Mini-Splatting.

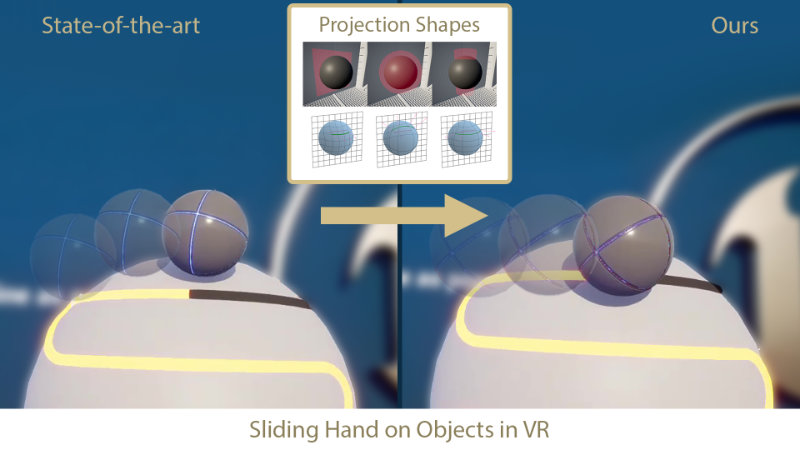
- Enhancing the Precision of a User’s Hand When Sliding on Objects in VR
- Anna Kozłowska, Mikołaj Wójcik, Maciej Spychała, Joanna Porter-Sobieraj and Jakub Ciecierski
- DOI link
-
Abstract
Interaction in virtual reality (VR) remains a major research challenge, due to the difficulty of accurately reproducing a user's position, the differences that exist between the virtual and real worlds, and the need to ensure a faster response than in traditional computer systems. Our work focuses on software-based approaches that support the user's hand running over VR objects. Existing constraint-based methods implemented in game engines result in visible glitches which negatively affect the user's immersion.
To mitigate this, we have developed an easy-to-implement human-object interface based on auxiliary projection shapes. Our method, like other software-centered solutions, does not require any additional advanced haptic hardware; it relies solely on a standard VR headset (HMD) with controllers. The evaluation performed confirmed that our approach allows smooth motion to be attained in a 3D scene without adding additional latency to the VR system. Furthermore, for different projection shapes, different hand behavior on the same 3D object is obtained. As a result, scene designers are offered a simple visual mechanism to manipulate hand motion on 3D objects' surfaces, enhancing its precision while sliding to create more desirable hand trajectories.
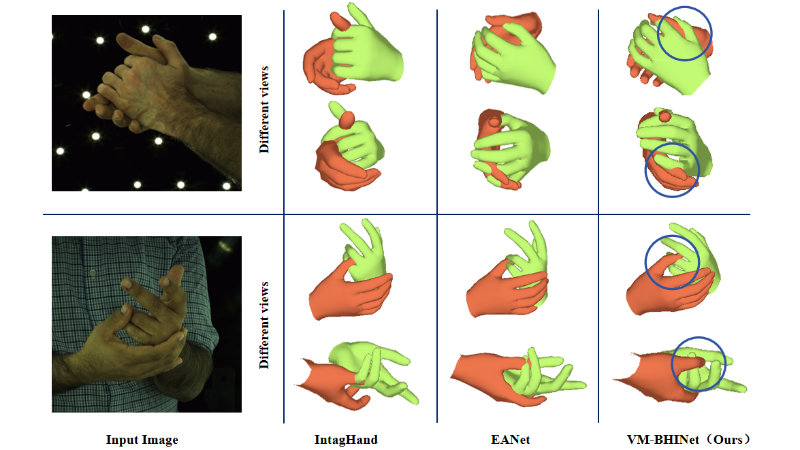
- VM-BHINet: Vision Mamba Bimanual Hand Interaction Network for 3D Interacting Hand Mesh Recovery From a Single RGB Image
- Han Bi, Ge Yu, Yu He, Wenzhuo Liu and Zijie Zheng
- DOI link
-
Abstract
Understanding bimanual hand interactions is essential for realistic 3D pose and shape reconstruction. However, existing methods struggle with occlusions, ambiguous appearances, and computational inefficiencies.
To address these challenges, we propose Vision Mamba Bimanual Hand Interaction Network (VM-BHINet), introducing state space models (SSMs) into hand reconstruction to enhance interaction modeling while improving computational efficiency. The core component, Vision Mamba Interaction Feature Extraction Block (VM-IFEBlock), combines SSMs with local and global feature operations, enabling deep understanding of hand interactions. Experiments on the InterHand2.6M dataset show that VM-BHINet reduces MPJPE and MPVPE by 2-3%, significantly surpassing state-of-the-art methods.
- Generalized, Dynamic Multi-agent Torso Crowds
- Bilas Talukdar and Tomer Weiss
- DOI link
-
Abstract
In crowd simulation algorithms, discs are commonly used due to their geometrical simplicity. However, discs overestimate the body's projected shape on the ground plane, and do not naturally embody rotational information for each crowd agent.
We propose a crowd simulation algorithm that represents crowd agents as 2D capsules. Our algorithm is based on position-based dynamics (PBD), for which we design novel constraints for capturing dynamics for capsule-shaped agents. We demonstrate our algorithm in several scenarios, showing superior performance compared to a disc-based representation on settings that range from sparse to dense.

Papers 2: Simulation
- Session chair: Bartlomiej Wronski
- A Robust and Generalized Gauss-Seidel Solver for Physically-Correct Simultaneous Collisions
- Huanbo Zhou, Zhenyu Xu, Xijun Liu and Xinyu Zhang
- DOI link
-
Abstract
Simulating multi-object collisions in real-time environments remains a significant challenge, particularly when handling simultaneous collisions in a physically accurate manner. Traditional Gauss-Seidel solvers, widely employed in physics engines, often fail to preserve the symmetry and consistency for multi-object interactions that are often observed in physics.
In this paper, we present a generalized and robust Gauss-Seidel solver to overcome the difficulties in simultaneous collisions. Using spatial and temporal collision states to classify and resolve constraints, our algorithm ensures correct collision propagation and symmetry, addressing limitations commonly found in existing solvers. Moreover, our algorithm can mitigate jitters caused by floating-point errors, ensuring smooth and stable collision responses. Our approach demonstrates fast convergence and improved accuracy in scenarios involving complex multi-object collisions.
- An Incompressible Crack Model for Volume Preserving MPM Fracture
- Shiguang Liu, Maolin Wu, Chenfanfu Jiang and Yisheng Zhang
- DOI link
-
Abstract
This paper proposes a novel method to simulate the dynamic fracture effect of elastoplastic objects. Our method is based on the continuum damage mechanics (CDM) theory and uses the material point method (MPM) to discretize the governing equations. Our proposed approach distinguishes itself from previous works by incorporating a novel method for modeling decohesion, which preserves the incompressibility of the cracks.
In contrast to existing methods that rely on material stiffness degradation, our approach leverages carefully crafted constitutive models for both fully and partially damaged materials. We further introduce a novel granular material model that effectively captures the physical behavior of fully damaged debris. This is augmented by a volume-aware deformation gradient tensor designed to evaluate and stabilize material expansion. We conduct a comprehensive evaluation of our proposed method on multiple dynamic fracturing scenarios and demonstrate its effectiveness in producing visually richer and more realistic behaviors compared to previous state-of-the-art MPM approaches.
- Thunderscapes: Simulating the Dynamics of Mesoscale Convective System
- Tianchen Hao, Jinxian Pan, Yangcheng Xiang, Xiangda Shen, Xinsheng Li and Yanci Zhang
- DOI link
-
Abstract
A Mesoscale Convective System (MCS) is a collection of thunderstorms operating as a unified system, showcasing nature's untamed power. They represent a phenomenon widely referenced in both the natural sciences and the visual effects (VFX) industries. However, in computer graphics, visually accurate simulation of MCS dynamics remains a significant challenge due to the inherent complexity of atmospheric microphysical processes.
To achieve a high level of visual quality while ensuring practical performance, we introduce Thunderscapes, the first physically based simulation framework for visually realistic MCS tailored to graphical applications.
Our model integrates mesoscale cloud microphysics with hydrometeor electrification processes to simulate thunderstorm development and lightning flashes. By capturing various thunderstorm types and their associated lightning activities, Thunderscapes demonstrates the versatility and physical accuracy of the proposed approach.

- Arc Blanc: a real time ocean simulation framework
- David Algis, Bérenger Bramas, Emmanuelle Darles and Lilian Aveneau
- (invited JCGT paper presentation) DOI link
-
Abstract
The oceans cover the vast majority of the Earth. Therefore, their simulation has many scientific, industrial and military interests, including computer graphics domain. By fully exploiting the multi-threading power of GPU and CPU, current state-of-the-art tools can achieve real-time ocean simulation, even if it is sometimes needed to reduce the physical realism for large scenes. Although most of the building blocks for implementing an ocean simulator are described in the literature, a clear explanation of how they interconnect is lacking.
Hence, this paper proposes to bring all these components together, detailing all their interactions, in a comprehensive and fully described real-time framework that simulates the free ocean surface and the coupling between solids and fluid. This article also presents several improvements to enhance the physical realism of our model. The two main ones are: calculating the real-time velocity of ocean fluids at any depth; computing the input of the fluid to solid coupling algorithm.
Papers 3: Animation & Voxels
- Session chair: Paul Torrens
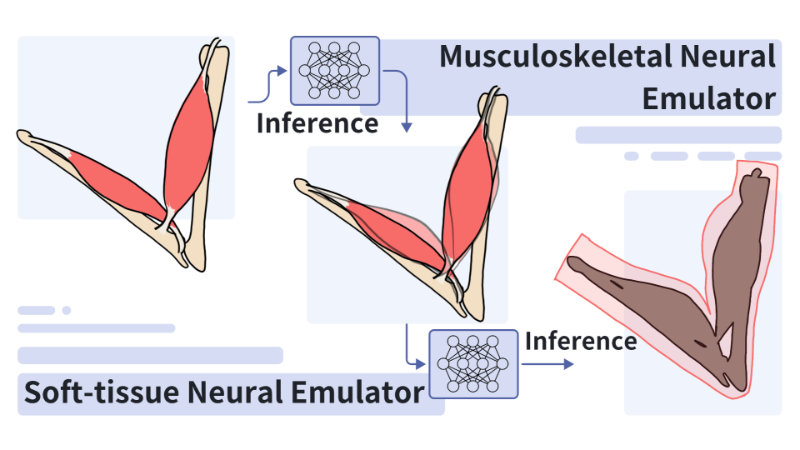
- Hierarchical Neural Skinning Deformation with Self-supervised Training for Character Animation
- Tianyi Wang and Shiguang Liu
- DOI link
-
Abstract
We propose a self-supervised neural deformation method for character skin deformation animations, incorporating musculoskeletal and adipose tissue deformations driven by joint movements. This hierarchical approach combines two self-supervised neural emulators: the musculoskeletal neural emulator, based on a biomaterial musculoskeletal model, and the soft-tissue neural emulator, capturing soft secondary dynamics. The neural emulators achieve self-supervised learning through a loss function derived from physical principles, eliminating the need for ground-truth datasets. The musculoskeletal neural emulator enhances deformation effects, including musculoskeletal bulging, contraction, and dynamic responses, and generates inner-layer animations.
Building on this, the soft-tissue neural emulator adds enhanced deformation effects, such as secondary motion, driven by the inner-layer animations. During inference, the method efficiently simulates realistic skin deformation animations for arbitrary character structures and joint motion sequences. The resulting animations demonstrate visual fidelity comparable to, or surpassing, state-of-the-art data-driven methods in the industry.
- Foveated Animations for Efficient Crowd Simulation
- Florin-Vladimir Stancu, Tomer Weiss and Rafael Kuffner dos Anjos
- DOI link
-
Abstract
Foveated rendering techniques have seen recent development with the advent of commercial head-mounted displays with eye-tracking capabilities. The main drive is to exploit particular features of our peripheral vision that allow optimizing rendering pipelines, which allows using less computational effort where the human visual system may be unaware of differences. Most efforts have been focused on simplifying spatial visual detail on areas not being focused on by adjusting acuity of shading models, sharpness of images, and pixel density. However, other perception pipeline areas are also influential, particularly in certain purpose-specific applications.
In this paper, we demonstrate it is possible to reduce animation rates in crowd simulations up to a complete stop for agents in our peripheral vision without users noticing the effect. We implemented a prototype Unity3D application with typical crowd simulation scenarios and carried out user experiments to study subjects' perception to changes in animation rates. We find that in the best case we were able to reduce the number of operations by 99.3% compared to an unfoveated scenario, with opportunities for developments combined with other acceleration techniques. This paper also includes an in-depth discussion about human perception of movement in peripheral vision with novel ideas that will have applications beyond crowd simulation.

- Aokana: A GPU-Driven Voxel Rendering Framework for Open World Games
- Yingrong Fang, Qitong Wang and Wei Wang
- DOI link
-
Abstract
Voxels are one of the most popular 3D geometric representations today. Due to their intuitiveness and ease of editing for non-professionals, voxels have been widely adopted in stylized games and low-cost independent games. However, the high storage cost of voxels, along with the significant time overhead associated with large-scale voxel rendering, limits the further development of open-world voxel games.
In this paper, we propose a GPU-Driven Voxel Rendering Framework for Open World Games (Aokana) based on a Sparse Voxel Directed Acyclic Graph (SVDAG). The framework incorporates a Level of Details (LOD) mechanism and a streaming system, enabling seamless map loading as players navigate the open world game environment. We also designed a corresponding high-performance GPU-driven voxel rendering pipeline to support real-time rendering of voxel scenes containing tens of billions of voxels. Our framework presented can be directly applied to existing game engines and seamlessly integrated with mesh-based rendering methods, making it suitable for practical game development. As the resolution of voxel scenes increases, our method reduces memory usage to about one-third to one-tenth of that of previous methods, while achieving rendering speeds that are 2 to 4 times faster.

- Transform-Aware Sparse Voxel Directed Acyclic Graphs
- Mathijs Molenaar and Elmar Eisemann
- DOI link
-
Abstract
Sparse Voxel Directed Acyclic Graphs (SVDAGs) have proven to be an efficient data structure for storing sparse binary voxel scenes. The SVDAG exploits repeating geometric patterns; which can be improved when considering mirror symmetries. We extend the previous work by providing a generalized framework to efficiently involve additional types of transformations and propose a novel translation matching for even more geometry reuse. Our new data structure is stored using a novel pointer encoding scheme to achieve a practical reduction in memory usage.

Papers 4: Filtering & Reconstruction
- Session chair: Takahiro Harada
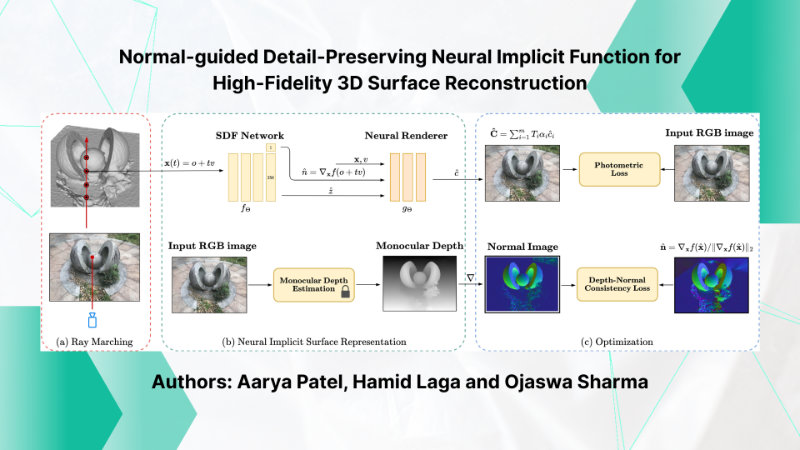
- Normal-guided Detail-Preserving Neural Implicit Function for High-Fidelity 3D Surface Reconstruction
- Aarya Patel, Hamid Laga and Ojaswa Sharma
- DOI link
-
Abstract
Neural implicit representations have emerged as a powerful paradigm for 3D reconstruction. However, despite their success, existing methods fail to capture fine geometric details and thin structures, especially in scenarios where only sparse multi-view RGB images of the objects of interest are available.
In this paper, we show that training neural representations with first-order differential properties (surface normals) leads to highly accurate 3D surface reconstruction, even with as few as two RGB images. Using input RGB images, we compute approximate groundtruth surface normals from depth maps produced by an off-the-shelf monocular depth estimator. During training, we directly locate the surface point of the SDF network and supervise its normal with the one estimated from the depth map. Extensive experiments demonstrate that our method achieves state-of-the-art reconstruction accuracy with a minimal number of views, capturing intricate geometric details and thin structures that were previously challenging to capture. The source code and additional results are available at https://sn-nir.github.io.
- Non-uniform Point Cloud Upsampling via Local Manifold Distribution
- Yao Hui Fang and Xing Ce Wang
- DOI link
-
Abstract
Existing learning-based point cloud upsampling methods often overlook the intrinsic data distribution characteristics of point clouds, leading to suboptimal results when handling sparse and non-uniform point clouds. We propose a novel approach to point cloud upsampling by imposing constraints from the perspective of manifold distributions.
Leveraging the strong fitting capability of Gaussian functions, our method employs a network to iteratively optimize Gaussian components and their weights, accurately representing local manifolds. By utilizing the probabilistic distribution properties of Gaussian functions, we construct a unified statistical manifold to impose distribution constraints on the point cloud. Experimental results on multiple datasets demonstrate that our method generates higher-quality and more uniformly distributed dense point clouds when processing sparse and non-uniform inputs, outperforming state-of-the-art point cloud upsampling techniques.
- Improved Stochastic Texture Filtering Through Sample Reuse
- Bartlomiej Wronski, Matt Pharr and Tomas Akenine-Möller
- DOI link
-
Abstract
Stochastic texture filtering (STF) has re-emerged as a technique that can be combined with advanced texture compression methods, e.g., neural texture compression, to bring down the cost of texture sampling and filtering. However, during texture magnification, the swapped order of filtering and shading with STF can result in aliasing and the inability to smoothly interpolate surface curvature represented in normal maps, leading to undesirable appearance changes.
We present a novel method for improving the quality of stochastically-filtered magnified textures with a small increase in cost that reduces the image difference compared to traditional texture filtering. We use the fact that when textures are magnified, nearby pixels filter similar sets of texels and therefore propose techniques for sharing texel values among pixels. We further propose an improvement to weighted importance sampling that guarantees that our method never increases error beyond single-sample stochastic texture filtering. Under high magnification, our method has >10 dB higher PSNR than single-sample STF. Our results show greatly improved image quality both with and without spatiotemporal denoising.
- GPU Friendly Laplacian Texture Blending
- Bartlomiej Wronski
- (invited JCGT paper presentation) DOI link
-
Abstract
Texture and material blending is one of the leading methods for adding variety to rendered virtual worlds, creating composite materials, and generating procedural content. When done naively, it can introduce either visible seams or contrast loss, leading to an unnatural look not representative of blended textures. Earlier work proposed addressing this problem through careful manual parameter tuning, lengthy per-texture statistics precomputation, look-up tables, or training deep neural networks.
In this work, we propose an alternative approach based on insights from image processing and Laplacian pyramid blending. Our approach does not require any precomputation or increased memory usage (other than the presence of a regular, non-Laplacian, texture mipmap chain), does not produce ghosting, preserves sharp local features, and can run in real time on the GPU at the cost of a few additional lower mipmap texture taps.
Papers 5: Rendering
- Session chair: Chris Wyman
- Real-Time Markov Chain Path Guiding for Global Illumination and Single Scattering
- Lucas Domingo Alber, Johannes Hanika and Carsten Dachsbacher
- DOI link
-
Abstract
We present a lightweight and unbiased path guiding algorithm tailored for real-time applications with highly dynamic content. The algorithm demonstrates effectiveness in guiding both direct and indirect illumination. Moreover, it can be extended to guide single scattering events in participating media. Building upon the screen-space approach by Dittebrandt et al. [2023], the incident light distribution is represented as a von Mises-Fisher mixture model, which is controlled by a Markov chain process.
To extend the procedure to world space, our algorithm uses a unique Markov chain architecture, which resamples Markov chain states from an ensemble of hash grids. We combine multi-resolution adaptive grids with a static grid, ensuring rapid state exchange without compromising guiding quality. The algorithm imposes minimal prerequisites on scene representation and seamlessly integrates into existing path tracing frameworks. Through continuous multiple importance sampling, it remains independent of the equilibrium distribution of Markov chain and hash grid resampling. We perform an evaluation of the proposed methods across diverse scenarios. Additionally, we explore the algorithm’s viability in offline scenarios, showcasing its effectiveness in rendering volumetric caustics. We demonstrate the application of the proposed methods in a path tracing engine for the original Quake game. The demo project features path traced global illumination and single scattering effects at frame rates over 30 FPS on NVIDIA’s GeForce 20 series or AMD’s Radeon RX 6000 series without upscaling.

- Joint Denoising and Upscaling via Multi-branch and Multi-scale Feature Network
- Pawel Kazmierczyk, Sungye Kim, Wojciech Uss, Wojciech Kalinski, Tomasz Galaj, Mateusz Maciejewski and Rama Harihara
- DOI link
-
Abstract
Deep learning-based denoising and upscaling techniques have emerged to enhance framerates for real-time rendering. A single neural network for joint denoising and upscaling offers the advantage of sharing parameters in the feature space, enabling efficient prediction of filter weights for both. However, it is still ongoing research to devise an efficient feature extraction neural network that uses different characteristics in inputs for the two combined problems.
We propose a multi-branch, multi-scale feature extraction network for joint neural denoising and upscaling. The proposed multi-branch U-Net architecture is lightweight and effectively accounts for different characteristics in noisy color and noise-free aliased auxiliary buffers. Our technique produces superior quality denoising in a target resolution (4K), given noisy 1spp Monte Carlo renderings and auxiliary buffers in a low resolution (1080p), compared to the state-of-the-art methods.

- EON: A practical energy-preserving rough diffuse BRDF
- Jamie Portsmouth, Peter Kutz and Stephen Hill
- (invited JCGT paper presentation) DOI link
-
Abstract
We introduce the energy-preserving Oren-Nayar (EON) model for reflection from rough surfaces. Unlike the popular qualitative Oren–Nayar model (QON) and its variants, our model is energy preserving via analytical energy compensation. We include self-contained GLSL source code for efficient evaluation of the new model and importance sampling based on a novel technique we term Clipped Linearly Transformed Cosine (CLTC) sampling.
- A Stack-Free Traversal Algorithm for Left-Balanced k-d Trees
- Ingo Wald
- (invited JCGT paper presentation) DOI link
-
Abstract
We present an algorithm that allows for find-closest-point and k-nearest-neighbor (kNN) style traversals of left-balanced k-d trees, without the need for either recursion or software-managed stacks; instead using only current and last previously traversed node to compute which node to traverse next.
Papers 6: Neural & Splatting
- Session chair: Sungye Kim
- LSNIF: Locally-Subdivided Neural Intersection Function
- Shin Fujieda, Chih-Chen Kao and Takahiro Harada
- DOI link
-
Abstract
Neural representations have shown the potential to accelerate ray casting in a conventional ray-tracing-based rendering pipeline.
We introduce a novel approach called Locally-Subdivided Neural Intersection Function (LSNIF) that replaces bottom-level BVHs used as traditional geometric representations with a neural network. Our method introduces a sparse hash grid encoding scheme incorporating geometry voxelization, a scene-agnostic training data collection, and a tailored loss function. It enables the network to output not only visibility but also hit-point information and material indices. LSNIF can be trained offline for a single object, allowing us to use LSNIF as a replacement for its corresponding BVH. With these designs, the network can handle hit-point queries from any arbitrary viewpoint, supporting all types of rays in the rendering pipeline. We demonstrate that LSNIF can render a variety of scenes, including real-world scenes designed for other path tracers, while achieving a memory footprint reduction of up to 106.2 times compared to a compressed BVH.

- VR-Splatting: Foveated Radiance Field Rendering via 3D Gaussian Splatting and Neural Points
- Linus Franke, Laura Fink and Marc Stamminger
- DOI link
-
Abstract
Recent advances in novel view synthesis have demonstrated impressive results in fast photorealistic scene rendering through differentiable point rendering, either via Gaussian splatting (3DGS) [Kerbl et al. 2023] or neural point rendering [Aliev et al. 2020]. Unfortunately, these directions require either a large number of small Gaussians or expensive per-pixel post-processing for reconstructing fine details, which negatively impacts rendering performance. With the high performance demands of virtual reality~(VR) systems, primitive or pixel counts therefore have to be kept low, affecting visual quality.
In this paper, we propose foveated rendering as a promising solution, allowing the combination of the strengths of both point rendering directions regarding performance sweet spots in a novel hybrid approach. Analyzing the compatibility with the human visual system, we note that using a low-detailed, few primitive smooth Gaussian representation for the periphery is cheap to compute and meets the perceptual demands of peripheral vision. For the fovea, we use neural points with a convolutional neural network for the small pixel footprint of the fovea only, which provides sharp, detailed output within the rendering budget. Fusing these elements also allows for synergistic method accelerations with point occlusion culling and reducing the demands on the neural network. Our evaluation confirms that our approach increases sharpness and details compared to a standard VR-ready 3DGS configuration and participant of a user study overwhelmingly preferred our method. Our system meets the necessary performance requirements for real-time VR interactions, ultimately enhancing the user's immersive experience.

- ESCT3D: Efficient and Selectively Controllable Text-Driven 3D Content Generation with Gaussian Splatting
- Huiqi Wu, Li Yao, Jianbo Mei, Yingjie Huang, Yining Xu, Jingjiao You and Yilong Liu
- DOI link
-
Abstract
In recent years, significant advancements have been made in text-driven 3D content generation. However, several challenges remain. In practical applications, users often provide extremely simple text inputs while expecting high-quality 3D content. Generating optimal results from such minimal text is a difficult task due to the strong dependency of text-to-3D models on the quality of input prompts. Moreover, the generation process exhibits high variability, making it difficult to control. Consequently, multiple iterations are typically required to produce content that meets user expectations, reducing generation efficiency.
To address this issue, we propose GPT-4V for self-optimization, which significantly enhances the efficiency of generating satisfactory content in a single attempt. Furthermore, the controllability of text-to-3D generation methods has not been fully explored. Our approach enables users to not only provide textual descriptions but also specify additional conditions, such as style, edges, scribbles, poses, or combinations of multiple conditions, allowing for more precise control over the generated 3D content. Additionally, during training, we effectively integrate multi-view information, including multi-view depth, masks, features, and images, to address the common Janus problem in 3D content generation. Extensive experiments demonstrate that our method achieves robust generalization, facilitating the efficient and controllable generation of high-quality 3D content.

- SplatMAP: Online Dense Monocular SLAM with 3D Gaussian Splatting
- Yue Hu, Rong Liu, Meida Chen, Peter Beerel and Andrew Feng
- DOI link
-
Abstract
Achieving high-fidelity 3D reconstruction from monocular video remains challenging due to the inherent limitations of traditional methods like Structure-from-Motion (SfM) and monocular SLAM in accurately capturing scene details. While differentiable rendering techniques such as Neural Radiance Fields (NeRF) address some of these challenges, their high computational costs make them unsuitable for real-time applications. Additionally, existing 3D Gaussian Splatting (3DGS) methods often focus on photometric consistency, neglecting geometric accuracy and failing to exploit SLAM's dynamic depth and pose updates for scene refinement.
We propose a framework integrating dense SLAM with 3DGS for real-time, high-fidelity dense reconstruction. Our approach introduces SLAM-Informed Adaptive Densification, which dynamically updates and densifies the Gaussian model by leveraging dense point clouds from SLAM. Additionally, we incorporate Geometry-Guided Optimization, which combines edge-aware geometric constraints and photometric consistency to jointly optimize appearance and geometry of the 3DGS scene representation, enabling detailed and accurate SLAM mapping reconstruction. Experiments on the Replica and TUM-RGBD datasets demonstrate the effectiveness of our approach, achieving state-of-the-art results among monocular systems.
Specifically, our method achieves a PSNR of 36.864, SSIM of 0.985, and LPIPS of 0.040 on Replica, representing improvements of 10.7%, 6.4%, and 49.4%, respectively, over the previous SOTA. On TUM-RGBD, our method outperforms the closest baseline by 10.2%, 6.6%, and 34.7% in the same metrics. These results highlight the potential of our framework in bridging the gap between photometric and geometric dense 3D scene representations, paving the way for practical and efficient monocular dense reconstruction. A demonstration of the results can be found in the accompanying video: https://youtu.be/Pr_kyWQQkGo.

Contact
Send questions to general@i3dsymposium.org for general inquiries, registration, and sponsorship.
Direct queries about paper submissions to papers@i3dsymposium.org and poster submissions to posters@i3dsymposium.org.