
- Papers 1: Interaction and VR
- Papers 2: Light Transport and Storage
- Papers 3: Volumes and Fields
- Papers 4: Points and Splats
- Papers 5: Noise and Reconstruction
- Papers 6: Efficient Forward and Differentiable Rendering
- Papers 7: Learning to Move
- Papers 8: Solvers and Simulation
Over the past three decades, the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games has showcased exceptional progress from academic and industrial research covering all aspects of interactive computer graphics.
This year, we continue a track record of excellence with 23 high-quality papers selected by the international paper committee for publication and presentation at the conference.
Conference papers have been published in PACM CGIT. We will also publish links to author versions of the papers as they provide them. Refresh this page periodically, or use a web page monitoring tool, to check this page for updates. Also, in the meantime, you can check Ke-Sen’s page where they are also collecting material for these papers:
https://www.realtimerendering.com/kesen/i3d2024Papers.htm
Invited papers
The program also includes 3 papers originally published in the IEEE Transactions on Visualization and Computer Graphics (TVCG) that will be presented during the conference.
Papers 1: Interaction and VR
- Session chair: Omer Shapira
- Watch Video
- Collaborating with my Doppelgänger: The Effects of Self-similar Appearance and Voice of a Virtual Character during a Jigsaw Puzzle Co-solving Task
- Siqi Guo, Minsoo Choi, Dominic Kao and Christos Mousas
- DOI link, preprint, presentation
-
Abstract
The research community has long been interested in human interaction with embodied virtual characters in virtual reality (VR). At the same time, interaction with self-similar virtual characters, or virtual doppelgängers, has become a prominent topic in both VR and psychology due to the intriguing psychological effects these characters can have on people. However, studies on human interaction with self-similar virtual characters are still limited.
To address this research gap, we designed and conducted a 2 (appearance: self-similar vs. non-self-similar appearance) x 2 (voice: self-similar vs. non-self-similar voice) within-group study (N=25) to explore how combinations of appearance and voice factors influence participants' perception of virtual characters. During the study, we asked participants to collaborate with a virtual character in solving a VR jigsaw puzzle. After each experimental condition, we had participants complete a survey about their experiences with the virtual character.
Our findings showed that 1) the virtual characters' self-similarity in appearance enhanced the sense of co-presence and perceived intelligence, but it also elicited higher eeriness; 2) the self-similar voices led to higher ratings on the characters' likability and believability; however, they also induced a more eerie sensation; and 3) we observed an interaction effect between appearance and voice factors for ratings on believability, where the virtual characters were considered more believable when their self-similarity in appearance matched that of their voices. This study provided valuable insights and comprehensive guidance for creating novel collaborative experiences with self-similar virtual characters in immersive environments.

- Perceptions of Hybrid Lighting for Virtual Reality
- Martin Dinkov, Sumanta Pattanaik and Ryan McMahan
- DOI link
-
Abstract
Virtual reality (VR) applications are computationally demanding due to high frame rate requirements, which precludes large numbers of realtime lights from being used.
In this paper, we explore a hybrid lighting approach that combines the benefits of realtime and baked lights based on the importance of each source. First, we demonstrate that the hybrid approach affords better frames per second than realtime and mixed lighting (which combines the direct qualities of realtime and the indirect qualities of baked lighting). We then present the results of an online paired-comparison study, in which participants (n=60) compared videos of the four lighting conditions (baked, mixed, realtime, and hybrid) in terms of preference.
Our results indicate that the hybrid lighting approach is better than realtime lighting in terms of graphical performance and also yields better perceptions of quality for scenes with a small to moderately large number of lights.

- Skill-Based Matchmaking for Competitive Two-Player Games
- Cem Yuksel
- DOI link, preprint, presentation
-
Abstract
Skill-based matchmaking is a crucial component of competitive multiplayer games and it is directly tied to how the players would enjoy the game.
We present a simple matchmaking algorithm that aims to achieve a target win rate for all players, making long win/loss streaks less probable. It is based on the estimated rating of players. Therefore, we also present a raking estimation for players that does not require any game-specific information and purely relies on game outcomes. Our evaluation shows that our methods are effective in estimating a player’s rating, responding to changes in rating, and achieving a desirable win rate that avoids long win/loss streaks in competitive two-player games.

- Impact of Tutorial Modes with Different Time Flow Rates in Virtual Reality Games
- Boyuan Chen, Xinan Yan, Xuning Hu, Dominic Kao and Hai-Ning Liang
- DOI link, preprint, presentation
-
Abstract
The disparities between virtual reality (VR) technology and traditional media make VR games to adopt innovative interaction modes and tutorial methodologies. Existing research in related fields predominantly concentrates on the performance of VR tutorial modes, such as the placement of text and diagrams within tutorial content. However, few studies have delved into other attributes of tutorials. This study categorizes 4 VR game tutorial modes based on the time flow: traditional instruction screen, slow motion, bullet time, and context-sensitive mode.
This paper evaluates the impact of these 4 VR game tutorial modes with varying time flow rates on control learnability, engagement-related outcomes, and player performance. We conducted a between-subjects experiment with 59 participants. Results indicated that bullet time significantly enhanced control learnability, reduced cognitive load, and improved player performance when compared to other tutorial modes.
Our research contributes to a more comprehensive understanding of VR game tutorials and offers practical guidance for game designers, underscoring the potential of bullet time to enhance learnability and game experience.
Papers 2: Light Transport and Storage
- Session chair: William Donnelly
- Watch Video
- Bounded VNDF Sampling for the Smith–GGX BRDF
- Yusuke Tokuyoshi and Kenta Eto
- DOI link, preprint, presentation
-
Abstract
Sampling according to a visible normal distribution function (VNDF) is often used to sample rays scattered by glossy surfaces, such as the Smith–GGX microfacet model. However, for rough reflections, existing VNDF sampling methods can generate undesirable reflection vectors occluded by the surface. Since these occluded reflection vectors must be rejected, VNDF sampling is inefficient for rough reflections.
This paper introduces an unbiased method to reduce the number of rejected samples for Smith–GGX VNDF sampling. Our method limits the sampling range for a state-of-the-art VNDF sampling method that uses a spherical cap-based sampling range. By using our method, we can reduce the variance for highly rough and low-anisotropy surfaces. Since our method only modifies the spherical cap range in the existing sampling routine, it is simple and easy to implement.

- ZH3: Quadratic Zonal Harmonics
- Thomas Roughton, Peter-Pike Sloan, Ari Silvennoinen, Michal Iwanicki and Peter Shirley
- DOI link, preprint, presentation
-
Abstract
Spherical Harmonics (SH) have been used widely to represent lighting in games and film. While the quadratic (SH3) and higher order spherical harmonics represent irradiance well, they are expensive to store and evaluate, requiring 27 coefficients per sample. Linear SH (SH2), requiring only 12 coefficients, are sometimes used, but they do not represent irradiance signals accurately and can have challenges with negative reconstruction.
We introduce a new representation (ZH3) that augments linear SH with just the zonal coefficient of quadratic SH, yielding significant visual improvement with just 15 coefficients, and discuss how solving for a luminance zonal axis can significantly improve reconstruction accuracy and reduce color artifacts. We also discuss how, rather than storing the ZH3 coefficients explicitly, we can hallucinate them from the linear SH, improving reconstruction accuracy over linear SH at minimal extra cost.

- Interactive Rendering of Caustics using Dimension Reduction for Manifold Next-Event Estimation
- Ana Granizo-Hidalgo and Nicolas Holzschuch
- DOI link, preprint, presentation
-
Abstract
Specular surfaces, like water surfaces, create caustics by focusing the light being refracted or reflected. These caustics are very important for scene realism, but also challenging to render: to compute them, we need to find the exact path connecting two points through a specular reflection or refraction. This requires finding the roots of a complicated function on the surface. Manifold-Exploration methods find these roots using the Newton-Raphson method, but this involves computing path derivatives at each step, which can be challenging.
We show that these roots lie on a curve on the surface, which reduces the dimensionality of the search. This dimension reduction greatly improves the search, allowing for interactive rendering of caustics. It also makes implementation easier, as we do not need to compute path derivatives.

Papers 3: Volumes and Fields
- Session chair: Ricardo Marroquim
- Watch Video
- ProteusNeRF: Fast Lightweight NeRF Editing using 3D-Aware Image Context
- Binglun Wang, Niladri Shekhar Dutt and Niloy Mitra
- DOI link, preprint, presentation
-
Abstract
Neural Radiance Fields (NeRFs) have recently emerged as a popular option for photo-realistic object capture due to their ability to faithfully capture high-fidelity volumetric content even from handheld video input. Although much research has been devoted to efficient optimization leading to real-time training and rendering, options for interactive editing NeRFs remain limited.
We present a very simple but effective neural network architecture that is fast and efficient while maintaining a low memory footprint. This architecture can be incrementally guided through user-friendly image-based edits. Our representation allows straightforward object selection via semantic feature distillation at the training stage. More importantly, we propose a local 3D-aware image context to facilitate view-consistent image editing that can then be distilled into fine-tuned NeRFs, via geometric and appearance adjustments. We evaluate our setup on a variety of examples to demonstrate appearance and geometric edits and report 10-30× speedup over concurrent work focusing on text-guided NeRF editing.

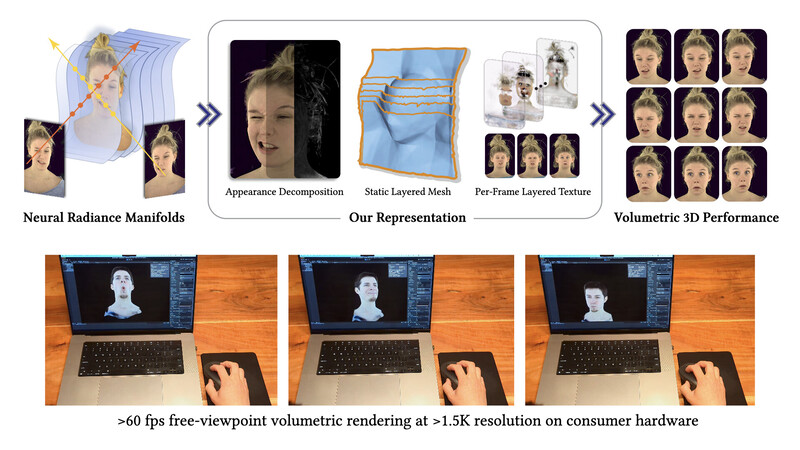
- FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
- Safa Medin, Gengyan Li, Ruofei Du, Stephan Garbin, Philip Davidson, Gregory Wornell, Thabo Beeler and Abhimitra Meka
- DOI link, preprint
-
Abstract
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts—photorealism, efficiency, compatibility, and configurability.
We present a novel representation that enables high-quality volumetric rendering of an actor’s dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
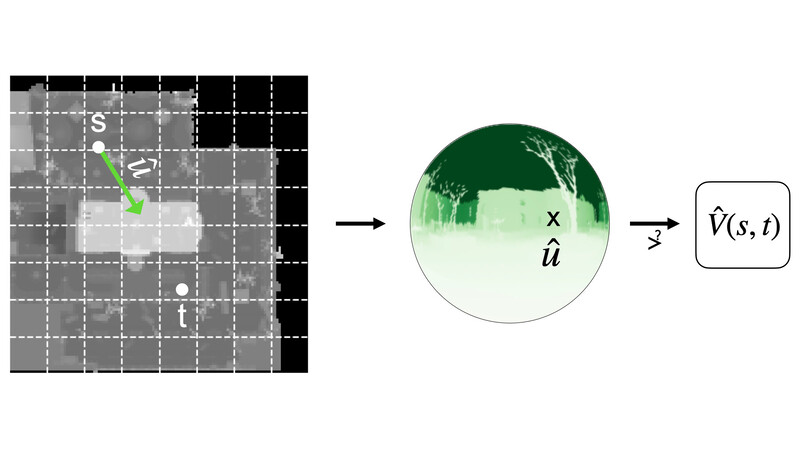
- Efficient Visibility Approximation for Game AI using Neural Omnidirectional Distance Fields
- Zhi Ying, Nicholas Edwards and Mikhail Kutuzov
- DOI link, preprint, presentation
-
Abstract
Visibility information is critical in game AI applications, but the computational cost of raycasting-based methods poses a challenge for real-time systems.
To address this challenge, we propose a novel method that represents a partitioned game scene as neural Omnidirectional Distance Fields (ODFs), allowing scalable and efficient visibility approximation between positions without raycasting. For each position of interest, we map its omnidirectional distance data from the spherical surface onto a UV plane. We then use multi-resolution grids and bilinearly interpolated features to encode directions. This allows us to use a compact multi-layer perceptron (MLP) to reconstruct the high-frequency directional distance data at these positions, ensuring fast inference speed. We demonstrate the effectiveness of our method through offline experiments and in-game evaluation.
For in-game evaluation, we conduct a side-by-side comparison with raycasting-based visibility tests in three different scenes. Using a compact MLP (128 neurons and 2 layers), our method achieves an average cold start speedup of 9.35 times and warm start speedup of 4.8 times across these scenes. In addition, unlike the raycasting-based method, whose evaluation time is affected by the characteristics of the scenes, our method's evaluation time remains constant.
Papers 4: Points and Splats
- Session chair: Peter Shirley
- Watch Video
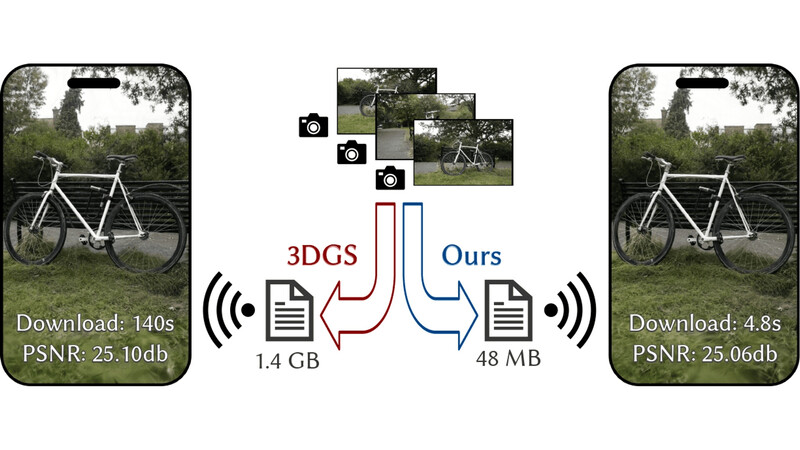
- Reducing the Memory Footprint of 3D Gaussian Splatting
- Panagiotis Papantonakis, Georgios Kopanas, Bernhard Kerbl, Alexandre Lanvin and George Drettakis
- DOI link, preprint, presentation
-
Abstract
3D Gaussian splatting provides excellent visual quality for novel view synthesis, with fast training and real-time rendering; unfortunately, the memory requirements of this method are unreasonably high. We first analyze the reasons for this, identifying three main areas where storage can be reduced: the number of 3D Gaussian primitives used to represent a scene, the number of coefficients for the spherical harmonics used to represent directional radiance and the precision required to store Gaussian primitive attributes.
We present a solution to each of these issues. First, we propose an efficient, resolution-aware primitive pruning approach, reducing primitive count by half. Second, we introduce an adaptive adjustment method to choose the number of coefficients used to represent directional radiance for each Gaussian primitive, and finally a codebook-based quantization method, together with a half-float representation for further memory reduction. Taken together, these three components result in a ×27 reduction in overall memory usage on the standard datasets we tested, along with a ×1.7 speedup in rendering speed. We demonstrate our method on standard datasets, and show how our solution results in significantly reduced download times when using the method on a mobile device.
- SimLOD: Simultaneous LOD Generation and Rendering for Point Clouds
- Markus Schütz, Lukas Herzberger and Michael Wimmer
- DOI link, preprint, presentation
-
Abstract
We propose an incremental LOD generation approach for point clouds that allows us to simultaneously load points from disk, update an octree-based level-of-detail representation, and render the intermediate results in real time while additional points are still being loaded from disk. LOD construction and rendering are both implemented in CUDA and share the GPU’s processing power, but each incremental update is lightweight enough to leave enough time to maintain real-time frame rates.
Background: LOD construction is typically implemented as a preprocessing step that requires users to wait before they are able to view the results in real time. This approach allows users to view intermediate results right away. Results: Our approach is able to stream points from an SSD and update the octree on the GPU at rates of up to 580 million points per second (~9.3GB/s from a PCIe 5.0 SSD) on an RTX 4090. Depending on the data set, our approach spends an average of about 1 to 2 ms to incrementally insert 1 million points into the octree, allowing us to insert several million points per frame into the LOD structure and render the intermediate results within the same frame.
Discussion/Limitations: We aim to provide near-instant, real-time visualization of large data sets without preprocessing. Out-of-core processing of arbitrarily large data sets and color-filtering for higher-quality LODs are subject to future work.

- Deblur-GS: 3D Gaussian Splatting from Camera Motion Blurred Images
- Wenbo Chen and Ligang Liu
- DOI link, preprint, presentation
-
Abstract
Novel view synthesis has undergone a revolution thanks to the radiance field method. The introduction of 3D Gaussian splatting (3DGS) has successfully addressed the issues of prolonged training times and slow rendering speeds associated with Neural Radiance Field (NeRF), all while preserving the quality of reconstructions. However, 3DGS remains heavily reliant on the quality of input images and their initial camera pose initialization. In cases where input images are blurred, the reconstruction results suffer from blurriness and artifacts.
In this paper, we propose the Deblur-GS method for reconstructing 3D Gaussian points to create a sharp radiance field from a camera motion blurred image set. We model the problem of motion blur as a joint optimization challenge involving camera trajectory estimation and time sampling. We cohesively optimize the parameters of the Gaussian points and the camera trajectory during the shutter time. Deblur-GS consistently achieves superior performance and rendering quality when compared to previous methods, as demonstrated in evaluations conducted on both synthetic and real datasets.

- Light Field Display Point Rendering
- Ajinkya Gavane and Benjamin Watson
- DOI link, presentation
-
Abstract
Rendering for light field displays (LFDs) requires rendering of dozens or hundreds of views, which must then be combined into a single image on the display, making real-time LFD rendering extremely difficult.
We introduce light field display point rendering (LFDPR), which meets these challenges by improving eye-based point rendering [12] with texture-based splatting, which avoids oversampling of triangles mapped to only a few texels; and with LFD-biased sampling, which adjusts horizontal and vertical triangle sampling to match the sampling of the LFD itself. To improve image quality, we introduce multiview mipmapping, which reduces texture aliasing even though compute shaders do not support hardware mipmapping. We also introduce angular supersampling and reconstruction to combat LFD view aliasing and crosstalk. The resulting LFDPR is 2-8× times faster than multiview rendering, with similar comparable quality.

Papers 5: Noise and Reconstruction
- Session chair: Eric Haines
- Watch Video
- FAST: Filter-Adapted Spatio-Temporal Sampling for Real-Time Rendering
- William Donnelly, Alan Wolfe, Judith Bütepage and Jon Valdés
- DOI link, preprint, presentation
-
Abstract
Stochastic sampling techniques are ubiquitous in real-time rendering, where performance constraints force the use of low sample counts, leading to noisy intermediate results. To remove this noise, the post-processing step of temporal and spatial denoising is an integral part of the real-time graphics pipeline.
The main insight presented in this paper is that we can optimize the samples used in stochastic sampling such that the post-processing error is minimized. The core of our method is an analytical loss function which measures post-filtering error for a class of integrands — multidimensional Heaviside functions. These integrands are an approximation of the discontinuous functions commonly found in rendering. Our analysis applies to arbitrary spatial and spatiotemporal filters, scalar and vector sample values, and uniform and non-uniform probability distributions. We show that the spectrum of Monte Carlo noise resulting from our sampling method is adapted to the shape of the filter, resulting in less noisy final images. We demonstrate improvements over state-of-the-art sampling methods in three representative rendering tasks: ambient occlusion, volumetric ray-marching, and color image dithering. Common use noise textures, and noise generation code is available in supplemental material.

- Filtering After Shading With Stochastic Texture Filtering
- Matt Pharr, Bartlomiej Wronski, Marco Salvi and Marcos Fajardo
- DOI link, preprint, presentation
-
Abstract
2D texture maps and 3D voxel arrays are widely used to add rich detail to the surfaces and volumes of rendered scenes, and filtered texture lookups are integral to producing high-quality imagery.
We show that applying the texture filter after evaluating shading generally gives more accurate imagery than filtering textures before BSDF evaluation, as is current practice. These benefits are not merely theoretical, but are apparent in common cases. We demonstrate that practical and efficient filtering after shading is possible through the use of stochastic sampling of texture filters.
Stochastic texture filtering offers additional benefits, including efficient implementation of high-quality texture filters and efficient filtering of textures stored in compressed and sparse data structures, including neural representations. We demonstrate applications in both real-time and offline rendering and show that the additional error from stochastic filtering is minimal. We find that this error is handled well by either spatiotemporal denoising or moderate pixel sampling rates.

- A Fast GPU Schedule For À-Trous Wavelet-Based Denoisers
- Reiner Dolp, Johannes Hanika and Carsten Dachsbacher
- DOI link, preprint
-
Abstract
Given limitations of contemporary graphics hardware, real-time ray-traced global illumination is only estimated using a few samples per pixel. This consequently causes stochastic noise in the resulting frame sequences which requires wide filter support during denoising for temporally stable estimates. The edge avoiding à-trous wavelet transform amortizes runtime cost by hierarchical filtering using a constant number of increasingly dilated tabs in each iteration. While the number of taps stays constant, the runtime of each iteration increases in these usually memory-throughput bound shaders with increasing dilation.
We present a scheduling approach that optimizes usage of the memory subsystem through permutation of global invocation indices and array index access functions. In contrast to prior approaches, our method has identical performance charateristics for each iteration, effectively decreasing maintenance cost and improving performance predictability. Furthermore, we are able to leverage on-chip memory and hardware texture interpolation. Our permutation strategy is trivial to integrate into existing wavelet filters as a permutation before and after each level of the wavelet filter. We achieve speedups between 1.3 and 3.8 for usual wavelet configurations in Monte Carlo denoising and computational photography.
- Cone-Traced Supersampling for Signed Distance Field Rendering
- Andrei Chubarau, Yangyang Zhao, Ruby Rao, Derek Nowrouzezahrai and Paul G. Kry
- (invited TVCG paper presentation) DOI link, presentation
-
Abstract
While signed distance fields (SDFs) in theory offer infinite level of detail, they are typically rendered using the sphere tracing algorithm at finite resolutions, which causes the common rasterized image synthesis problem of aliasing. Most existing optimized antialiasing solutions rely on polygon mesh representations; SDF-based geometry can only be directly antialiased with the computationally expensive supersampling or with post-processing filters that may produce undesirable blurriness and ghosting.
In this work, we present cone-traced supersampling (CTSS), an efficient and robust spatial antialiasing solution that naturally complements the sphere tracing algorithm, does not require casting additional rays per pixel or offline prefiltering, and can be easily implemented in existing real-time SDF renderers. CTSS performs supersampling along the traced ray near surfaces with partial visibility – object contours – identified by evaluating cone intersections within a pixel's view frustum.
We further introduce subpixel edge reconstruction (SER), a technique that extends CTSS to locate and resolve complex pixels with geometric edges in relatively flat regions, which are otherwise undetected by cone intersections. Our combined solution relies on a specialized sampling strategy to minimize the number of shading computations and correlates sample visibility to aggregate the samples. With comparable antialiasing quality at significantly lower computational cost, CTSS is a reliable practical alternative to conventional supersampling.
Papers 6: Efficient Forward and Differentiable Rendering
- Session chair: Michael Vance
- Watch Video
- Efficient Particle-Based Fluid Surface Reconstruction Using Mesh Shaders and Bidirectional Two-Level Grids
- Yuki Nishidate and Issei Fujishiro
- DOI link, presentation
-
Abstract
In this paper, we introduce a novel method for particle-based fluid surface reconstruction that incorporates mesh shaders for the first time.
This approach eliminates the need to store triangle meshes in the GPU's global memory, resulting in a significant memory size reduction.
Furthermore, our method employs a bidirectional two-level uniform grid, which not only accelerates the computationally expensive stage of surface cell detection but also effectively addresses the issue of vertex overflow among the mesh shaders.
Experimental results proved that our method outperforms the state-of-the-art method, achieving both acceleration and memory reduction simultaneously, without sacrificing quality.
The method is highly practical, with no major limitations other than requiring a GPU that supports the mesh shaders.

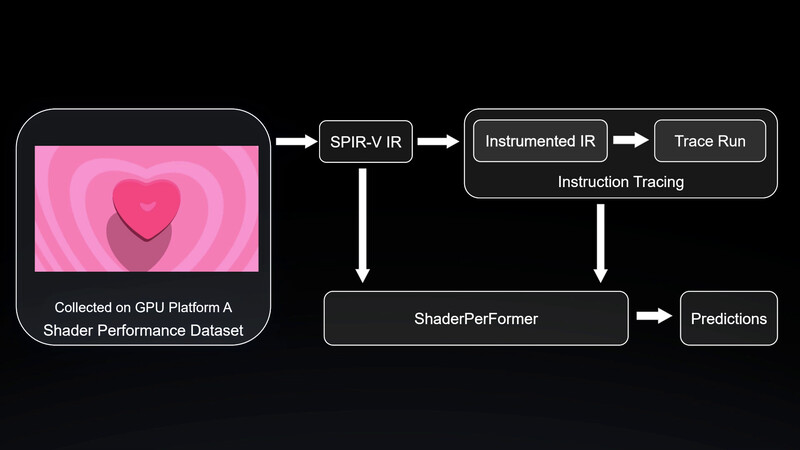
- ShaderPerFormer: Platform-independent Context-aware Shader Performance Predictor
- Zitan Liu, Yikai Huang and Ligang Liu
- DOI link, preprint, presentation
-
Abstract
The ability to model and predict execution time of GPU computations is crucial for real-time graphics application development and optimization. While there are many existing methodologies for graphics programmers to provide such estimates, those methods are often vendor-dependent, require the platforms to be tested, or fail to capture the contextual influences among shader instructions.
To address this challenge, we propose ShaderPerFormer, a platform-independent, context-aware deep-learning approach to model GPU performance and provide end-to-end performance predictions on a per-shader basis. In order to provide more accurate predictions, our method contains a separate stage to gather platform-independent shader program trace information.
We also provide a dataset consisting of a total of 54,667 fragment shader performance samples on 5 different platforms. Compared to the PILR and SH baseline methods, our approach reduces the average MAPE across five platforms by 8.26% and 25.25%, respectively.
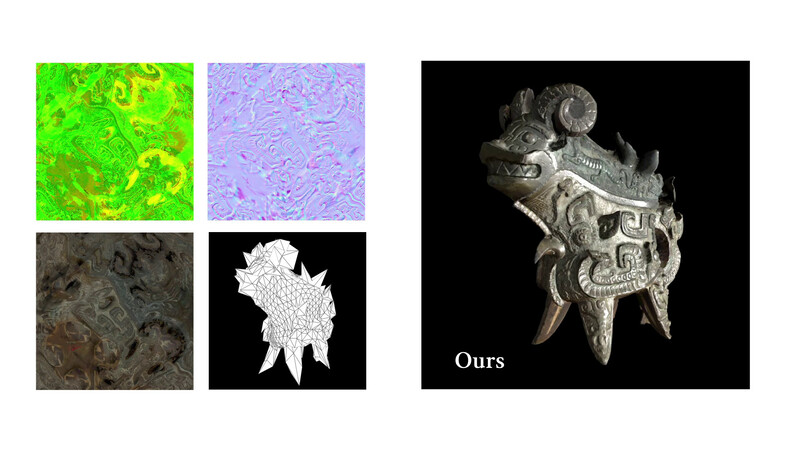
- Transforming a Non-Differentiable Rasterizer into a Differentiable One with Stochastic Gradient Estimation
- Thomas Deliot, Eric Heitz and Laurent Belcour
- DOI link, preprint, presentation
-
Abstract
We show how to transform a non-differentiable rasterizer into a differentiable one with minimal engineering efforts and no external dependencies (no Pytorch/Tensorflow). We rely on Stochastic Gradient Estimation, a technique that consists of rasterizing after randomly perturbing the scene's parameters such that their gradient can be stochastically estimated and descended. This method is simple and robust but does not scale in dimensionality (number of scene parameters).
Our insight is that the number of parameters contributing to a given rasterized pixel is bounded. Estimating and averaging gradients on a per-pixel basis hence bounds the dimensionality of the underlying optimization problem and makes the method scalable. Furthermore, it is simple to track per-pixel contributing parameters by rasterizing ID- and UV-buffers, which are trivial additions to a rasterization engine if not already available. With these minor modifications, we obtain an in-engine optimizer for 3D assets with millions of geometry and texture parameters.
Papers 7: Learning to Move
- Session chair: Sylvain Lefebvre
- Watch Video
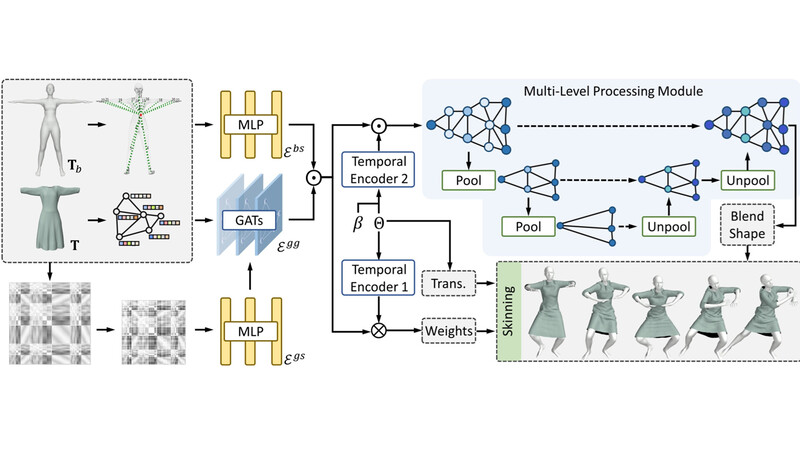
- Efficient Deformation Learning of Varied Garments with a Structure-Preserving Multilevel Framework
- Tianxing Li, Rui Shi, Zihui Li, Takashi Kanai and Qing Zhu
- DOI link, preprint, presentation
-
Abstract
Due to the highly nonlinear behavior of clothing, modelling fine-scale garment deformation on arbitrary meshes under varied conditions within a unified network poses a significant challenge. Existing methods often compromise on either model generalization, deformation quality, or runtime speed, making them less suitable for real-world applications.
To address it, we propose to incorporate multi-source graph construction and pooling to achieve a novel graph learning scheme. We first introduce methods for extracting cues from different deformation correlations and transform the garment mesh into a comprehensive graph enriched with deformation-related information.
To enhance the learning capability and generalizability of the model, we present structure-preserving pooling and unpooling strategies for the mesh deformation task, thereby improving information propagation across the mesh and enhancing the realism of deformation.
Lastly, we conduct an attribution analysis and visualize the contribution of various vertices in the graph to the output, providing insights into the deformation behavior. The experimental results demonstrate superior performance against state-of-the-art methods.
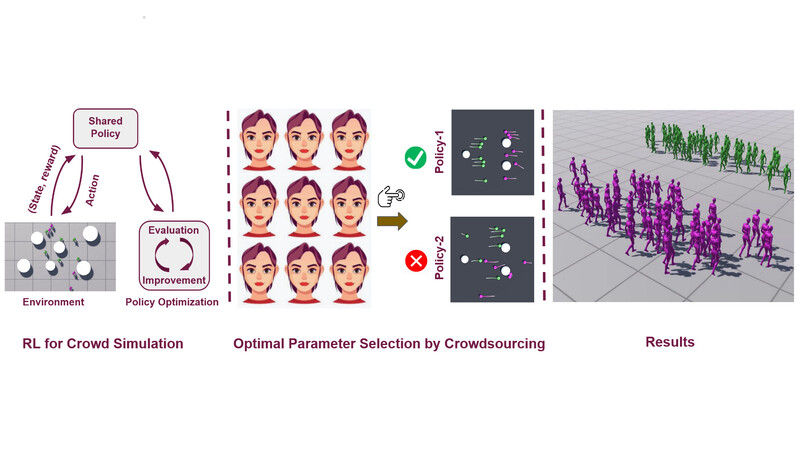
- Learning Crowd Motion Dynamics with Crowds
- Bilas Talukdar, Yunhao Zhang and Tomer Weiss
- DOI link, preprint, presentation
-
Abstract
Reinforcement Learning (RL) has become a popular framework for learning desired behaviors for computational agents in graphics and games. In a multi-agent crowd, one major goal is for agents to avoid collisions while navigating in a dynamic environment. Another goal is to simulate natural-looking crowds, which is difficult to define due to the ambiguity as to what is a natural crowd motion.
We introduce a novel methodology for simulating crowds, which learns most-preferred crowd simulation behaviors from crowd-sourced votes via Bayesian optimization. Our method uses deep reinforcement learning for simulating crowds, where crowd-sourcing is used to select policy hyper-parameters. Training agents with such parameters results in a crowd simulation that is preferred to users. We demonstrate our method's robustness in multiple scenarios and metrics, where we show it is superior compared to alternate policies and prior work.
Papers 8: Solvers and Simulation
- Session chair: Cem Yuksel
- Watch Video
- Windblown Sand Around Obstacles – Simulation And Validation Of Deposition Patterns
- Nicolas Rosset, Régis Duvigneau, Adrien Bousseau and Guillaume Cordonnier
- DOI link, preprint, presentation
-
Abstract
Sand dunes are iconic landmarks of deserts, but can also put human infrastructures at risk, for instance by forming near buildings or roads. We present a simulator of sand erosion and deposition to predict how dunes form around and behind obstacles under wind.
Inspired by both computer graphics and geo-sciences, our algorithm couples a fast wind flow simulation with physical laws of sand saltation and avalanching, which suffices to reproduce characteristic patterns of sand deposition. In particular, we validate our approach by reproducing real-world erosion and deposition measurements collected by prior work under controlled conditions.

- A Unified Particle-Based Solver for Non-Newtonian Behaviors Simulation
- Chunlei Li, Yang Gao, Jiayi He, Tianwei Cheng, Shuai Li, Aimin Hao and Hong Qin
- (invited TVCG paper presentation) DOI link, preprint, presentation
-
Abstract
In this paper, we present a unified framework to simulate non-Newtonian behaviors. We combine viscous and elasto-plastic stress into a unified particle solver to achieve various non-Newtonian behaviors ranging from fluid-like to solid-like.
Our constitutive model is based on a Generalized Maxwell model, which incorporates viscosity, elasticity and plasticity in one non-linear framework by a unified way. On the one hand, taking advantage of the viscous term, we construct a series of strain-rate dependent models for classical non-Newtonian behaviors such as shear-thickening, shear-thinning, Bingham plastic, etc. On the other hand, benefiting from the elasto-plastic model, we empower our framework with the ability to simulate solid-like non-Newtonian behaviors, i.e., visco-elasticity/plasticity.
In addition, we enrich our method with a heat diffusion model to make our method flexible in simulating phase change. Through sufficient experiments, we demonstrate a wide range of non-Newtonian behaviors ranging from viscous fluid to deformable objects. We believe this non-Newtonian model will enhance the realism of physically-based animation, which has great potential for computer graphics.
- MPMNet: A Data-Driven MPM Framework for Dynamic Fluid-Solid Interaction
- Jin Li, Yang Gao, Ju Dai, Shuai Li, Aimin Hao and Hong Qin
- (invited TVCG paper presentation) DOI link, preprint, presentation
-
Abstract
High-accuracy, high-efficiency physics-based fluid-solid interaction is essential for reality modeling and computer animation in online games or real-time Virtual Reality (VR) systems. However, the large-scale simulation of incompressible fluid and its interaction with the surrounding solid environment is either time-consuming or suffering from the reduced time/space resolution due to the complicated iterative nature pertinent to numerical computations of involved Partial Differential Equations (PDEs). In recent years, we have witnessed significant growth in exploring a different, alternative data-driven approach to addressing some of the existing technical challenges in conventional model-centric graphics and animation methods.
This paper showcases some of our exploratory efforts in this direction. One technical concern of our research is to address the central key challenge of how to best construct the numerical solver effectively and how to best integrate spatiotemporal/dimensional neural networks with the available MPM's pressure solvers. In particular, we devise the MPMNet, a hybrid data-driven framework supporting the popular and powerful Material Point Method (MPM), to combine the comprehensive properties of MPM in numerically handling physical behaviors ranging from fluid to deformable solids and the high efficiency of data-driven models. At the architectural level, our MPMNet comprises three primary components: A data processing module to describe the physical properties by way of the input fields; A deep neural network group to learn the spatiotemporal features; And an iterative refinement process to continue to reduce possible numerical errors. The goal of these special technical developments is to aim at involved numerical acceleration while preserving physical accuracy, realizing efficient and accurate fluid-solid interactions in a data-driven fashion. The extensive experimental results verify that our MPMNet can tremendously speed up the computation compared with the popular numerical methods as the complexity of interaction scenes increases while better retaining the numerical accuracy.
Contact
Send questions to general@i3dsymposium.org for general inquiries, registration, and sponsorship.
Direct queries about paper submissions to papers@i3dsymposium.org and poster submissions to posters@i3dsymposium.org.