
- Papers 1: VR in hard places
- Papers 2: Making characters behave
- Papers 3: Model glow-ups
- Papers 4: Shapes on track
- Papers 5: STIRring up the splatmosphere
- Papers 6: My game is all-a-stutter
Over the past four decades, the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games has showcased exceptional progress from academic and industrial research covering all aspects of interactive computer graphics, particularly games.
This year, we continue a track record of excellence with 16 high-quality papers selected by the international paper committee for publication and presentation at the conference.
Conference papers are published in PACM CGIT.
Invited papers
The program also includes 4 papers originally published in the IEEE journal Transactions on Games, which will be presented during the conference.
Papers 1: VR in hard places
- Session chair: Fabio Policarpo
- TrueForce: A Compliant Method for Perceptually Aligned Interaction with ETHD-Simulated Virtual Objects
- Yuqi Zhou and Voicu Popescu
- DOI link
-
Abstract
To enhance learning and training, VR haptic devices must provide safe and physically accurate feedback that helps users build intuitions about force and motion. We present SafeForce, a method for rendering force feedback by capturing user input and reconfiguring a compliant mechanism in real time to align perceived with expected forces. We implemented SafeForce in a grounded Encountered-Type Haptic Display (ETHD) and demonstrated its versatility through three representative physics scenarios: pushing a stationary object, experiencing electrostatic repulsion, and bouncing a moving object. A user study with 29 participants showed that users adapted to new interaction profiles within 2-3 trials, and that rendered forces remained within perceptual thresholds except in the heaviest and most dynamic conditions. These results suggest that SafeForce enables rapid, perceptually aligned, and educationally valuable interactions with moving virtual objects.
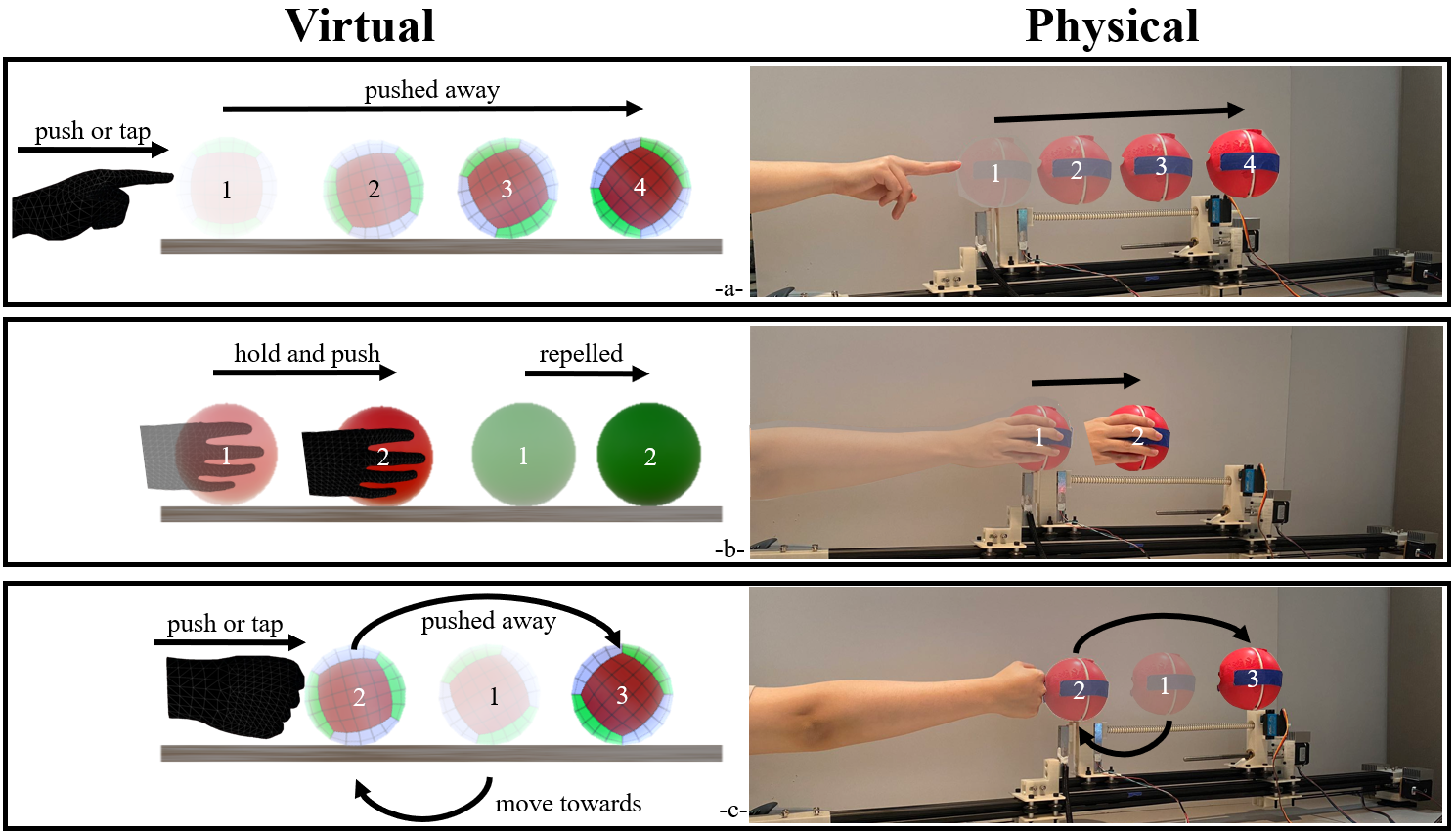
- Optical Flow-Based Anticipatory Audio Cues for Cybersickness Mitigation in Passive Navigation VR Environments
- Yuxue Bao, Xin Wang, Elliott Wen and Burkhard Wünsche
- DOI link
-
Abstract
Virtual reality (VR) applications face a critical trade-off: while visual immersion is the core experience, it often induces cybersickness (CS), leading to user attrition. Existing visual interventions (e.g., field-of-view restriction) alleviate discomfort at the cost of compromising immersion. Auditory interventions have been widely applied in mitigating motion sickness (MS), such as through music interventions and synchronized sound effects. Among all MS mitigation approaches, anticipatory audio cues have demonstrated effectiveness in vehicular MS contexts, reducing symptoms by approximately 17%. However, questions remain regarding VR cybersickness (CS): Do anticipatory audio cues remain effective in highly immersive virtual environments, where the dominance of visual interaction in VR may alter cue perception compared to that in MS contexts? How can VR motion intensity information be encoded, given that such information is largely absent in current mitigation strategies? How can anticipatory audio cues be systematically designed for CS mitigation through explicit mapping frameworks that link visual motion parameters to audio features? To address these gaps, this study establishes an optical flow mapping framework that encodes motion direction through stereo positioning and intensity through temporal patterns, delivering the results 2 seconds in advance. A within-subjects experiment (N = 24) was conducted in VR roller coaster environments, in which four conditions were compared. Results demonstrated a significant reduction in cybersickness across all audio conditions (direction-only: d = 0.862; intensity-only: d = 0.670; combined: d = 1.497, p < .001), with combined cues outperforming single-dimension alternatives (p < .016). All interventions preserved visual immersion (M ≈ 4.0/5) and maintained high usability metrics. This framework demonstrates that non-visual predictive cues can address the immersion-comfort trade-off in VR applications.

- Investigating the Effects of Physical Space Memory on User Performance in Virtual Reality
- Bing Ning and Mingtao Pei
- DOI link
-
Abstract
Virtual Reality offers highly immersive experiences, yet users remain physically situated in real-world environments whose layouts often differ from the virtual spaces they perceive. In these settings, users’ spatial memory of the physical environment may interact with or even conflict with the virtual scene, potentially influencing locomotion, task performance, and situational awareness. Despite its importance, the influence of physical space memory on VR interaction remains largely unexplored. To bridge this gap, we conducted three controlled studies that varied the virtual scene and task structure to examine how physical-space memory affects VR performance. In Study I, participants interacted with virtual props placed at different distances from real obstacles, returning to a fixed start point after each trial to isolate the effect of obstacle proximity on immediate strategies. Study II used the same setup but removed the resets, allowing us to observe how memory reliance changes as task duration increases. In Study III, we introduced virtual anchors with varying degrees of alignment to physical landmarks, assessing how spatial similarity between the two spaces influences navigation and task efficiency. Our findings reveal that users subconsciously adapt their navigation and decision-making based on remembered surroundings, even when no visual cues are available. These insights deepen our understanding of spatial cognition in immersive VR and provide actionable guidelines for designing safer, more efficient, and cognitively consistent virtual environments.

- CoVR: Bridging Heterogeneous Physical Spaces for Collaborative VR via Personalized Scene Layouts
- Bing Ning and Mingtao Pei
- DOI link
-
Abstract
Collaborative tasks in Virtual Reality, such as jointly manipulating objects, require tight multi-user synchronization. However, users often operate in heterogeneous physical environments with varying room sizes, furniture layouts, and obstacles. Enforcing a single, globally consistent virtual scene across such diversity constrains users’ natural movements, underutilizes available physical space, and ultimately degrades collaboration efficiency. We present CoVR, a novel framework that enables seamless multi-user collaboration in VR across heterogeneous physical spaces by prioritizing interaction alignment over strict spatial alignment. Instead of requiring all users to share an identical virtual scene, CoVR provides each user with a personalized virtual scene layout while maintaining synchronized actions and consistent collaborative outcomes. Technically, we formulate a multi-user coupled optimization problem that jointly optimizes per-user layouts to maximize usable space and facilitate seamless task execution. A key challenge arises from bi-directional dependencies: one user’s optimized layout determines feasible trajectories, which in turn constrain other users’ optimizations, and vice versa. To tackle this, CoVR introduces an iterative joint optimization algorithm alternating between personalized scene refinement and cross-user synchronization until convergence. We evaluate CoVR across typical collaborative tasks. Results show that CoVR significantly outperforms conventional scene alignment methods, leading to notable improvements in spatial efficiency, task completion time, and user comfort. These findings underscore its potential for scalable, natural, and efficient multi-user VR collaboration.

Papers 2: Making characters behave
- Session chair: Laura Reznikov
- Pose-Based Facial Animation Retargeting
- Hector Anadon Leon and Judith Bütepage
- DOI link
-
Abstract
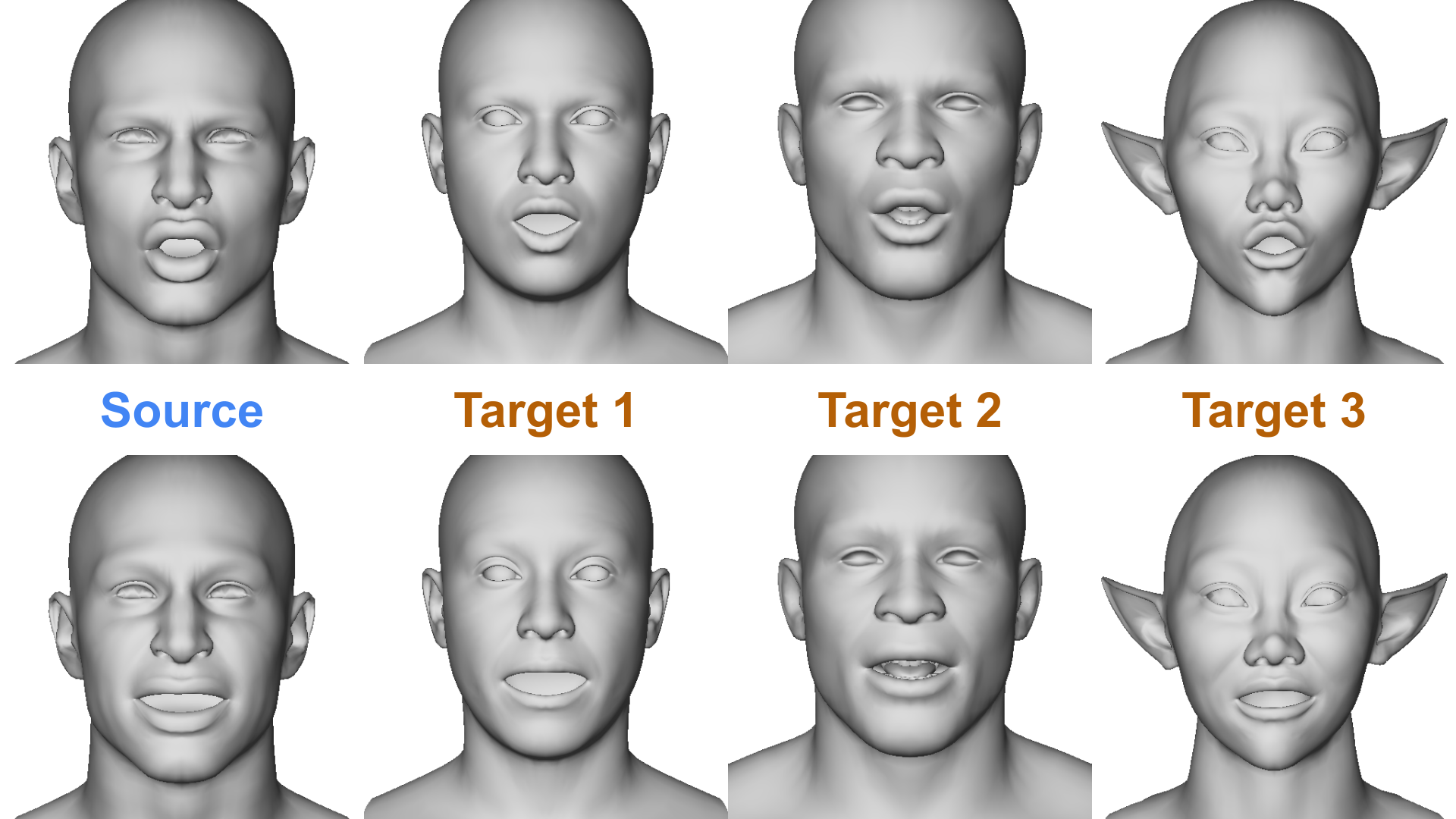
High-quality facial animation retargeting is crucial in digital entertainment production, enabling the transfer of animations from a source rig to a target rig. To avoid the need of manual transfer, automatic retargeting methods can be employed. However, creating universal methods remains challenging due to varying rig and topologies. We propose a novel retargeting method based on the idea that any facial expression can be decomposed into a weighted sum of Facial Action Coding System (FACS) poses. Our method assumes that these decompositions transfer across rigs with minimal need of refinement. We utilize a machine learning model to extract FACS weights from source frames. This model is trained solely on source animation data, requiring no target data or complex correspondence mappings. After a refinement step, these weights are then applied to the target rig’s FACS poses. Our technique supports seamless animation transfer across different rigs while allowing for artistic modifications by adjusting individual FACS poses. Our experiments demonstrate that this method produces high-quality retargeted animations and outperforms other retargeting methods. We explore how different design choices impact retargeting quality and showcase artistic control of asymmetries. By simplifying the workflow for rigged heads, this flexible framework enhances production efficiency while maintaining artistic control.
- Gen-C: Populating Virtual Worlds with Generative Crowds
- Andreas Panayiotou, Panayiotis Charalambous and Ioannis Karamouzas
- DOI link
-
Abstract
Over the past two decades, researchers have made significant steps in simulating agent-based human crowds, yet most efforts remain focused on low-level tasks such as collision avoidance, path following, and flocking. As a result, these approaches often struggle to capture the high-level behaviors that emerge from sustained agent-agent and agent-environment interactions over time. We introduce Generative LLM-Informed Modeling for Characters (GLIMC), a generative framework that produces crowd scenarios capturing agent–agent and agent–environment interactions, shaping coherent high-level crowd plans. To avoid the labor-intensive process of collecting and annotating real crowd video data, we leverage Large Language Models (LLMs) to bootstrap synthetic datasets of crowd scenarios. To represent those scenarios, we propose a time-expanded graph structure encoding actions, interactions, and spatial context. GLIMC employs a dual Variational Graph Autoencoder (VGAE) architecture that jointly learns connectivity patterns and node features conditioned on textual and structural signals, overcoming the limitations of direct LLM generation to enable scalable, environment-aware multi-agent crowd simulations. We demonstrate the effectiveness of our framework on scenarios with diverse behaviors such as, a University Campus and a Train Station, showing that it generates heterogeneous crowds, coherent interactions, and high-level decision-making patterns consistent with the provided context.

- Human-Like Bots for Tactical Shooters Using Compute-Efficient Sensors
- Niels Justesen, Maria Kaselimi, Sam Snodgrass, Miruna Vozaru, Matthew Schlegel, Jonas Wingren, Gabriella A. B. Barros, Tobias Mahlmann, Shyam Sudhakaran, Wesley Kerr, Albert Wang, Christoffer Holmgård, Georgios N. Yannakakis, Sebastian Risi and Julian Togelius
- (invited IEEE TRANSACTIONS ON GAMES paper presentation) DOI link
-
Abstract
Artificial intelligence (AI) has enabled agents to master complex video games, from first-person shooters, such as Counter-Strike, to real-time strategy games, such as StarCraft II, and racing games such as Gran Turismo. While these achievements are notable, applying these AI methods in commercial video game production remains challenging due to computational constraints. In commercial scenarios, the majority of computational resources are allocated to 3-D rendering, leaving limited capacity for AI methods, which often demand high computational power, particularly those relying on pixel-based sensors. Moreover, the gaming industry prioritizes creating human-like behavior in AI agents to enhance player experience, unlike academic models that focus on maximizing game performance. This article introduces a novel methodology for training neural networks via imitation learning to play a complex, commercial-standard, VALORANT-like 2v2 tactical shooter game, requiring only modest CPU hardware during inference. Our approach leverages an innovative, pixel-free perception architecture using a small set of ray-cast sensors, which capture essential spatial information efficiently. These sensors allow AI to perform competently without the computational overhead of traditional methods. Models are trained to mimic human behavior using supervised learning on human trajectory data, resulting in realistic and engaging AI agents. Human evaluation tests confirm that our AI agents provide human-like gameplay experiences while operating efficiently under computational constraints. This offers a significant advancement in AI model development for tactical shooter games and possibly other genres.

Papers 3: Model glow-ups
- Session chair: Niels Justesen
- PixelSync: Enhancing Texture Generation via Explicit Feature Synchronization
- Philipp Drescher, Edoardo A. Dominici, Giacomo Nazzaro, Konstantinos Vardis, Stefan Hauswiesner and Markus Steinberger
- DOI link
-
Abstract
The generation of consistent multi-view images is essential for diffusion-based 3D texture synthesis, a key component of modern 3D content pipelines. However, existing methods remain weakly coupled across viewpoints, often exhibiting inconsistencies between views that result in artifacts such as ghosting, misalignment, and texture distortions. We introduce PixelSync, a training-free mechanism that explicitly enforces multi-view consistency during the diffusion process. Our method operates in two stages. First, we compute visibility-aware pixel correspondences between known views in a fast pre-computation step by utilizing geometric information obtained from a given 3D model. Then, during the diffusion process, we enforce consistency through two complementary algorithms: (i) attention synchronization, by modifying the attention scores in the U-Net’s down- and mid-blocks, and (ii) latent synchronization, by progressively aligning features on their corresponding shared pixels. PixelSync can be seamlessly integrated into pre-trained diffusion models without retraining, offering a lightweight and effective solution. We demonstrate the effectiveness of our approach for generative texture synthesis by plugging PixelSync into established multi-view diffusion backbones, showcasing reduced cross-view artifacts and improved global coherence across standard quantitative and qualitative evaluations.

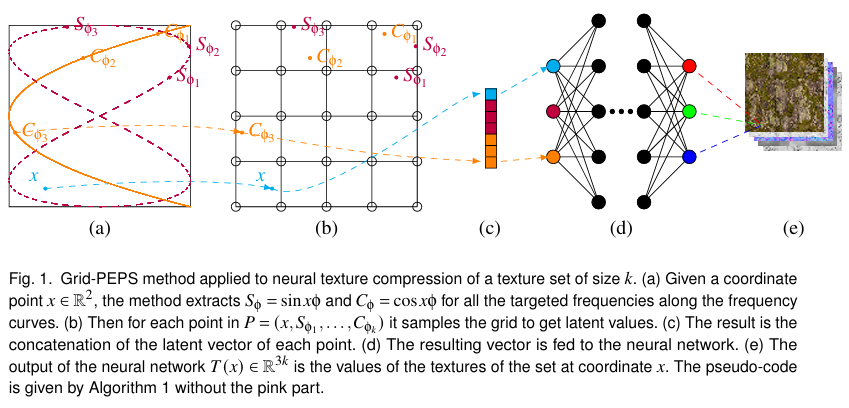
- PEPS: Positional Encoding Projected Sampling
- Guillaume Perez, Janarbek Matai and Takahiro Harada
- DOI link
-
Abstract
Implicit neural representations (INRs) are increasingly being used as tools to map coordinates to signals, encompassing applications from neural fields to texture compression, shape representations, and beyond. Most INR methods are based on using high-dimensional projections of the initial coordinates through encoders such as grid or positional encoding. Nevertheless, positional encoding is often insufficient and grids, as we show in this paper, require high resolution for being able to learn. In this paper, we demonstrate that positional encoding can be used not only as a high-dimensional embedding but also decomposed as a series of meaningful points. We propose the Positional Encoding Coordinate System, where we treat the projection of the original coordinate at each frequency as a point of interest. We describe the motion of each point with respect to the frequencies and show that it follows a unique pattern. Finally, we use the unique motion of each point as a basis decomposition for doing learned positional encoding using grids. We prove, using three competitive applications— image representation, texture compression, and signed distance function—that the proposed approach outperforms the current state of the art methods, and often requires 25% less parameters for equivalent reconstruction error or rendering.
- Aesthetic3D: Incorporating Shape Aesthetic Measures into 3D Modeling Interfaces
- Deng Yu, Jianing Guo, Hui Ye, Pengjie Ren, Hongbo Fu and Manfred Lau
- DOI link
-
Abstract
3D Aesthetics is significant in digital design, shaping how users experience real-time 3D content in games, VR, and product design. However, creating aesthetically pleasing shapes remains challenging due to diverse subjective standards and the lack of tools that support aesthetics-driven editing. Users often rely on intuition without explicit guidance on visual appeal, making aesthetic refinement slow, inconsistent, and cognitively demanding, particularly in fast-paced, iterative workflows. To address this challenge, we conducted in-depth interviews with design experts to identify challenges in aesthetics-oriented modeling workflows. Based on the findings, we developed Aesthetic3D, a 3D modeling interface offering real-time aesthetic scores learned from human perceptual data. Furthermore, Aesthetic3D seamlessly integrates the learned aesthetic measure into intuitive editing operations, enabling aesthetics-driven exploration and refinement of shape geometry. We evaluated Aesthetic3D through an ablation study, an open-ended study, and two generalization evaluations. Comprehensive experiments show that with Aesthetic3D, users can easily and effectively enhance the aesthetic appeal of 3D shapes.

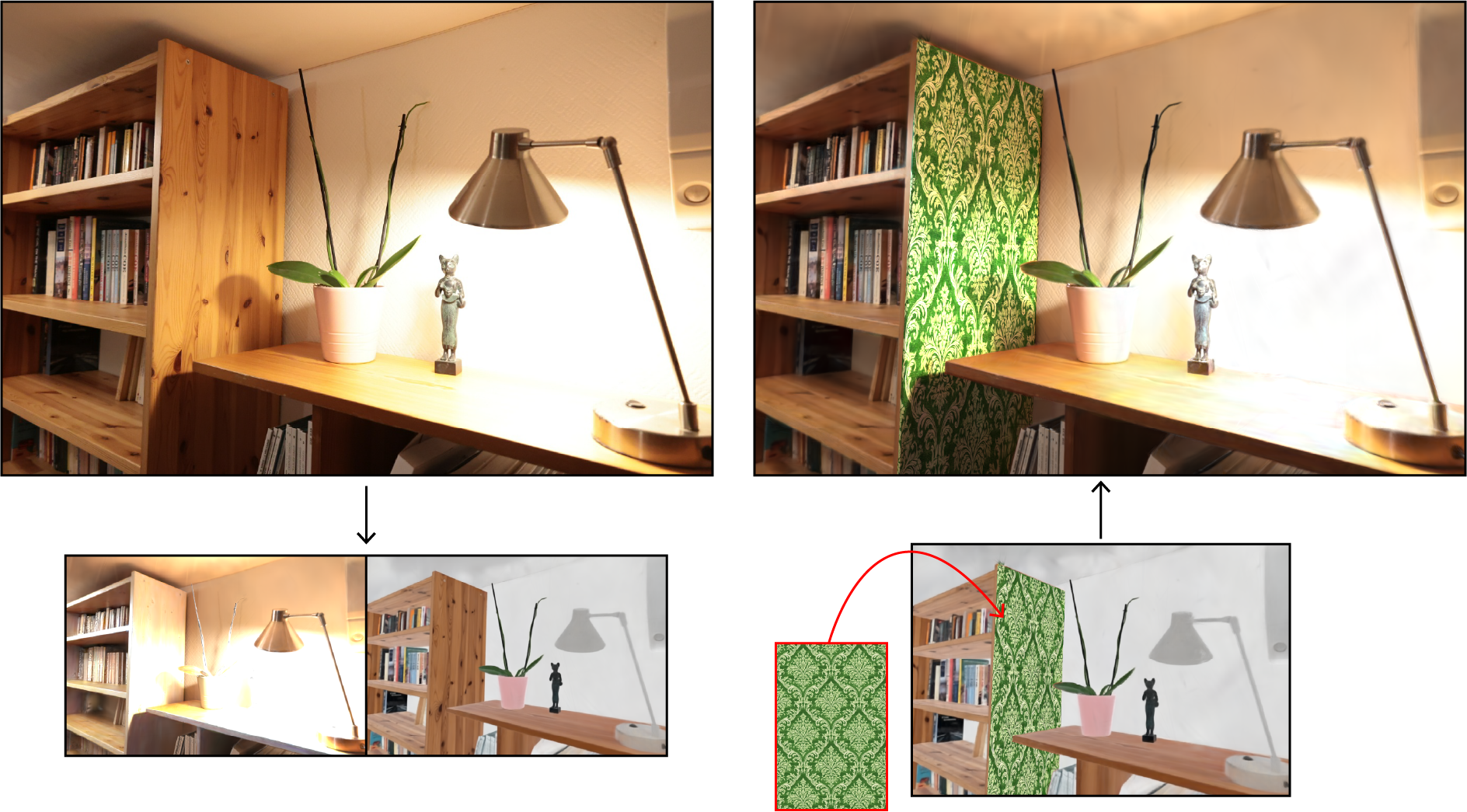
- Intrinsic decomposition and editing of 3D Gaussian splats
- Alexandre Lanvin, Jeffrey Hu, Simon Lucas, Adrien Bousseau and George Drettakis
- DOI link
-
Abstract
Intrinsic decomposition — which expresses image colors as the product of diffuse albedo and shading, possibly augmented with view-dependent residuals — has a long history in image editing as it enables the modification of object colors and textures without altering lighting. We extend intrinsic decomposition to radiance fields represented with Gaussian splatting by proposing solutions to three key aspects of such decomposition. First, we describe how to model the intrinsic decomposition as independent sets of Gaussian primitives, which allows each set to adapt to the characteristics of the layer it represents. Second, we present an optimization procedure guided by data-driven predictions to disentangle multi-view photographs of a scene into the aforementioned intrinsic sets. Finally, we provide an editing workflow where users modify the texture of planar surfaces simply by modifying the albedo of that surface in one image. Capturing this edit within the intrinsic radiance field allows re-rendering of the edited scene with plausible lighting under arbitrary viewpoints.
Papers 4: Shapes on track
- Session chair: Burkhard Wünsche
- From Generation to Gameplay: Authoring Race Tracks With Repulsive Curves
- Lasse Henrich and Falko Kötter
- (invited IEEE TRANSACTIONS ON GAMES paper presentation) DOI link
-
Abstract
Procedural content generation is a useful tool for content creation in computer games. We present a novel approach for generating closed, arcade-like race tracks. Our algorithm generates an initial shape by growing a curve inside a constrained space under self-repulsion, hence avoiding self-intersections while ensuring tight packing. This system is capable of generating a wide variety of closed race track shapes with deep customization options, like an isometric alignment of straight sections as developed here. Further, we devise algorithms for fitting the shape to a spline and introducing intersections, as well as fully generating a 3-D model with features like crossings and bridges. We extend this approach with an editor tool developed in the Unity Engine for easy access to controls and customization options, and conclude with an expressive range analysis of the generator's output.
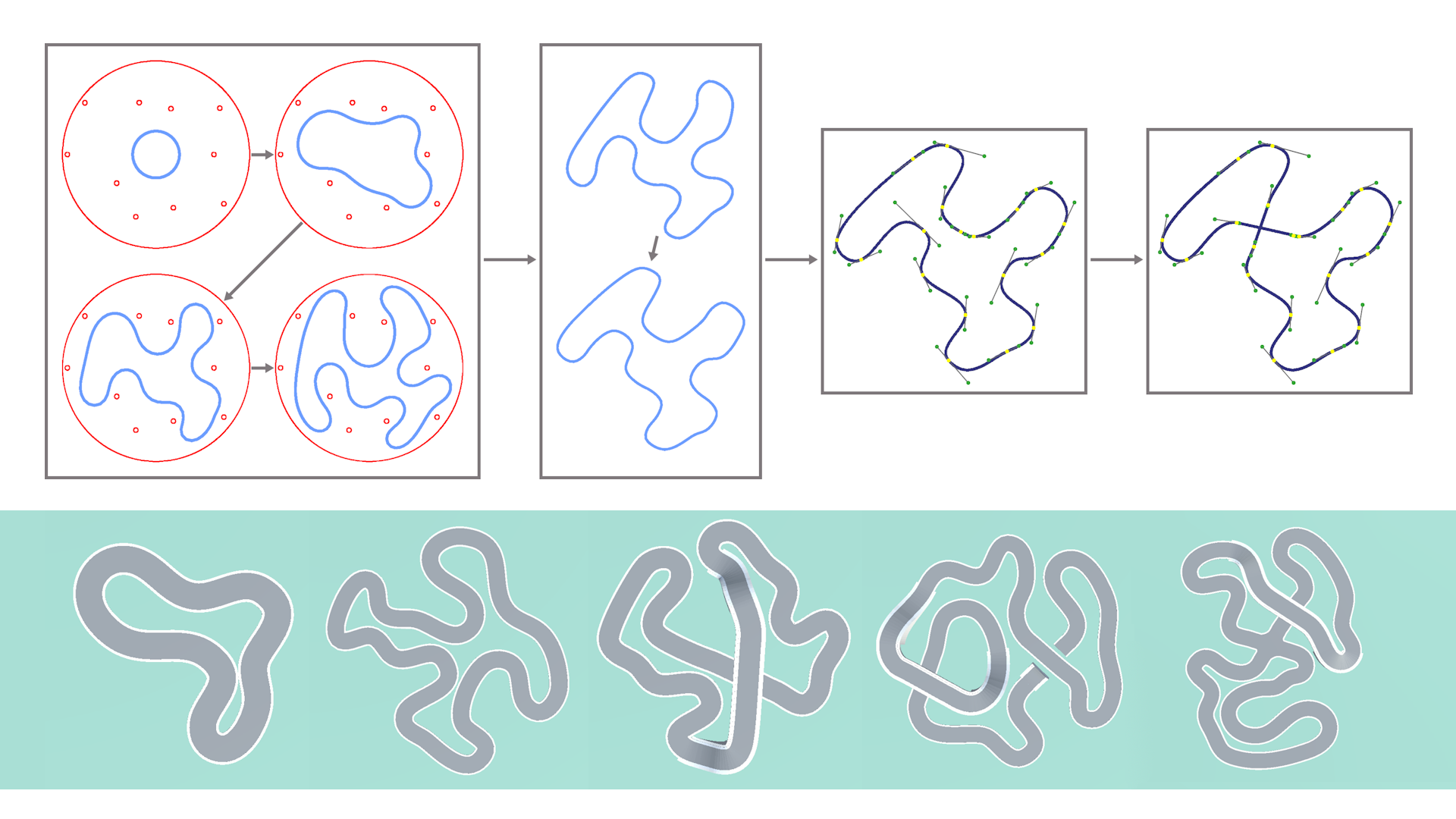
- Unpaired 3D Point Cloud Shape Translation through Structure-aware Token Space and Gated Fusion Translator
- Yu-Chiao Wu, I-Chen Lin, Tzu-Miao Yao and Po-Jui Lin
- DOI link
-
Abstract
This paper addresses the problem of unpaired shape translation on 3D point clouds. While prior methods typically rely on global latent vectors or spatially structured grids, such representations often lack the flexibility to capture both semantic structures and fine-grained geometric details. To address this, we propose operating directly in a structured token space, where tokens are pretrained through masked auto encoding. Unlike rigid spatial grids that impose fixed layouts, our tokens naturally adapt to geometric variations while maintaining semantic coherence. This structured yet flexible latent space enables semantically meaningful and geometrically precise transformations. A transformer-based translator is proposed to manipulate these tokens. This gated dual-branch translator enables detail-preserving and topology-aware shape translation across categories. Experiments on challenging tasks, such as chair-to-table transformations, demonstrate that our approach outperforms existing methods in preserving both global structure and part-level details.
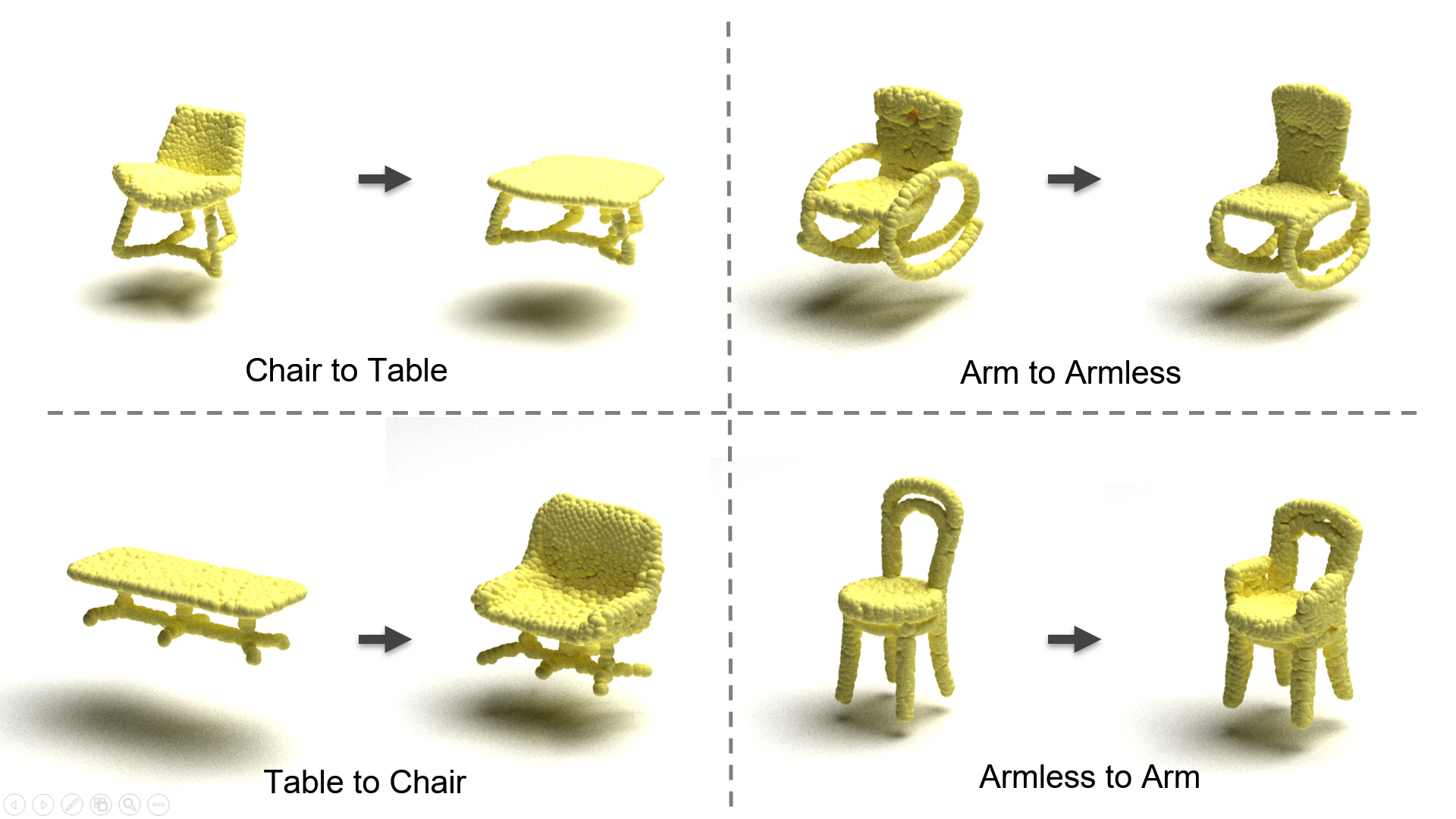
Papers 5: STIRring up the splatmosphere
- Session chair: Takahiro Harada
- ReSTIR PT Enhanced: Algorithmic Advances for Faster and More Robust ReSTIR Path Tracing
- Daqi Lin, Markus Kettunen and Chris Wyman
- DOI link
-
Abstract
Algorithms leveraging ReSTIR-style spatiotemporal reuse have recently proliferated, hugely increasing effective sample count for light transport in real-time ray and path tracers. Many papers have been published on novel theoretical improvements, but algorithmic improvements and engineering insights toward optimal implementation have largely been neglected. We demonstrate enhancements to ReSTIR PT that make it 2–3x faster, decrease both visual and numerical error, and improve its robustness, making it closer to production-ready. We halve the spatial reuse cost by reciprocal neighbor selection, robustify shift mappings with new footprint-based reconnection criteria, and reduce spatiotemporal correlation with duplication maps. We further improve both performance and quality by extensive optimization, unifying direct and global illumination into the same reservoirs, and utilizing existing techniques for color noise and disocclusion noise reduction.

- GRay: Ray Tracing 3D Gaussians Near The Speed of Splats
- Yohan Poirier-Ginter, Jean-François Lalonde and George Drettakis
- DOI link
-
Abstract
3D Gaussian Splatting is a popular representation for radiance field reconstruction, distinguished by the rendering speed of its rasterization-based renderer. While 3D Gaussians can also be raytraced, this approach has so far been slower, with 3D Gaussian Ray Tracing (3DGRT) taking nearly one order of magnitude longer to optimize. To address this, we present GRay, a fast ray tracer for 3D Gaussians designed to close this performance gap and match 3DGS's speed. Our method leverages the algorithmic difference between both approaches: unlike rasterization, ray tracing evaluates only Gaussians that are actually intersected by a ray, leading to potentially logarithmic—rather than linear—scaling in the number of primitives. This property allows ray tracing to better exploit dense scenes composed of numerous tiny Gaussians, a configuration which has largely been overlooked. Notably, we show that dense initialization—which creates many small primitives—slows down rasterization, but instead speeds up ray tracing. Designed to leverage this effect, GRay renders nearly 4× faster and optimizes nearly 10× faster than 3DGRT while maintaining similar quality, and has competitive speed with 3DGS albeit with somewhat lower quality. Code will be released upon publication.

- Improving Spatial Domain Repetition of Implicit Surfaces
- Clément Magniez and Cédric Zanni
- DOI link
-
Abstract
Implicit surfaces offer distinct advantages over traditional boundary representations, including infinite resolution, low memory footprint, smooth geometry by construction, and support for non-destructive modeling. In this work, we introduce a method for localizing geometric detail in a way that preserves the mathematical properties required for accurate and efficient rendering using sphere tracing. Our contributions include novel procedural modeling techniques that expand the range of repetition patterns achievable in implicit surfaces; an interpolation-based approach that maintains field correctness while remaining computationally efficient; and a cache-based acceleration strategy that significantly improves the rendering performance of domain-repeated implicit geometries.

Papers 6: My game is all-a-stutter
- Session chair: Justus Robertson
- Impact of Graphical Fidelity and Frame-Time Stutter in a First-Person Shooter Game
- Samin Shahriar Tokey, Ben Boudaoud, Joohwan Kim, Josef Spjut, Peter Xenopoulos and Mark Claypool
- DOI link
-
Abstract
Frametime spikes and graphical fidelity both influence the feel of first-person shooter (FPS) games, yet their combined effects are not well understood. This paper examines how graphics settings and frametime spike magnitude interact with player performance and experience. We developed a custom FPS game with configurable textures, lighting, and visual effects, and induced frametime spikes of 0~ms, 225~ms, or 675~ms during play. Twenty-one participants completed all combinations while providing performance data and subjective ratings for visual quality and smoothness. Results show that graphical fidelity primarily affects perceived visual quality, while frametime spikes strongly reduce perceived smoothness. Performance (i.e., score and accuracy) declines with larger spikes but remains largely unchanged across graphics settings. These findings suggest that spike magnitude, rather than graphical fidelity, is the dominant factor shaping smoothness and performance, while players still notice and prefer higher-fidelity visuals.

- A Toolkit for Visual Game Content Exploration and Modification
- Philipp Fleck, Michael Hochörtler, David Kastl, Georg Gotschier, Johanna Pirker and Dieter Schmalstieg
- (invited IEEE TRANSACTIONS ON GAMES paper presentation) DOI link
-
Abstract
We investigate the idea of a toolkit for visually exploring and modifying game content, addressing questions, such as how to identify relevant in-game data, how to make use of the data to create in-game visual representations, and what benefits these representations have. To that aim, we build a toolkit on top of the .NET platform employed by Unity in order to explore and add custom content without access to the game's source code. Our visual modifications use live objects in the game as data sources. The results appear as an integral part of the game world, which is generated with the original Unity rendering engine. This capability enables visual exploration for debugging, playtesting, modding, streaming, and data-driven analysis of games, as we demonstrate with several examples.

- Will GPT-4 Run DOOM?
- Adrian de Wynter
- (invited IEEE TRANSACTIONS ON GAMES paper presentation) DOI link
-
Abstract
We show that GPT-4’s reasoning and planning capabilities extend to the 1993 first-person shooter Doom. This large language model (LLM) is able to run and play the game with only a few instructions, plus a textual description–generated by the model itself from screenshots–about the state of the game being observed. We find that GPT-4 can play the game to a passable degree: it is able to manipulate doors, combat enemies, and perform pathing. More complex prompting strategies involving multiple model calls provide better results. While further work is required to enable the LLM to play the game as well as its classical, reinforcement learning-based counterparts, we note that GPT-4 required no training, leaning instead on its own reasoning and observational capabilities. We hope our work pushes the boundaries on intelligent, LLM-based agents in video games. We conclude by discussing the ethical implications of our work.

Contact
Send questions to general@i3dsymposium.org for general inquiries, registration, and sponsorship.
Direct queries about paper submissions to papers@i3dsymposium.org and poster submissions to posters@i3dsymposium.org.